
[핵심 답변]
Hash table을 사용하면 하나의 데이터를 탐색하는 시간은 O(1)로 b+tree보 다 빠르지만, 값이 정렬되어 있지 않기 때문에 부등호를 사용하는 query에 대해서는 매우 비효율적이게 되어 데이터를 정렬해서 저장하는 b+tree를 이용합니다.
[면접 꿀TIP]

하나의 값만 가져올 때는 hash table이 더 나을 수 있지만, 일정 범위의 값들을 찾을 때는 B+tree가 적합합니다. 이런 질문의 의도는, B+tree에 대해서 제대로 이해하고 있는지를 묻고 싶은 것입니다. 주로 B+tree로 구현되어 있는 index의 작동원리와 구조를 제대로 이해해 가시면 index에 대한 질문에는 더이상 막힐게 없습니다.
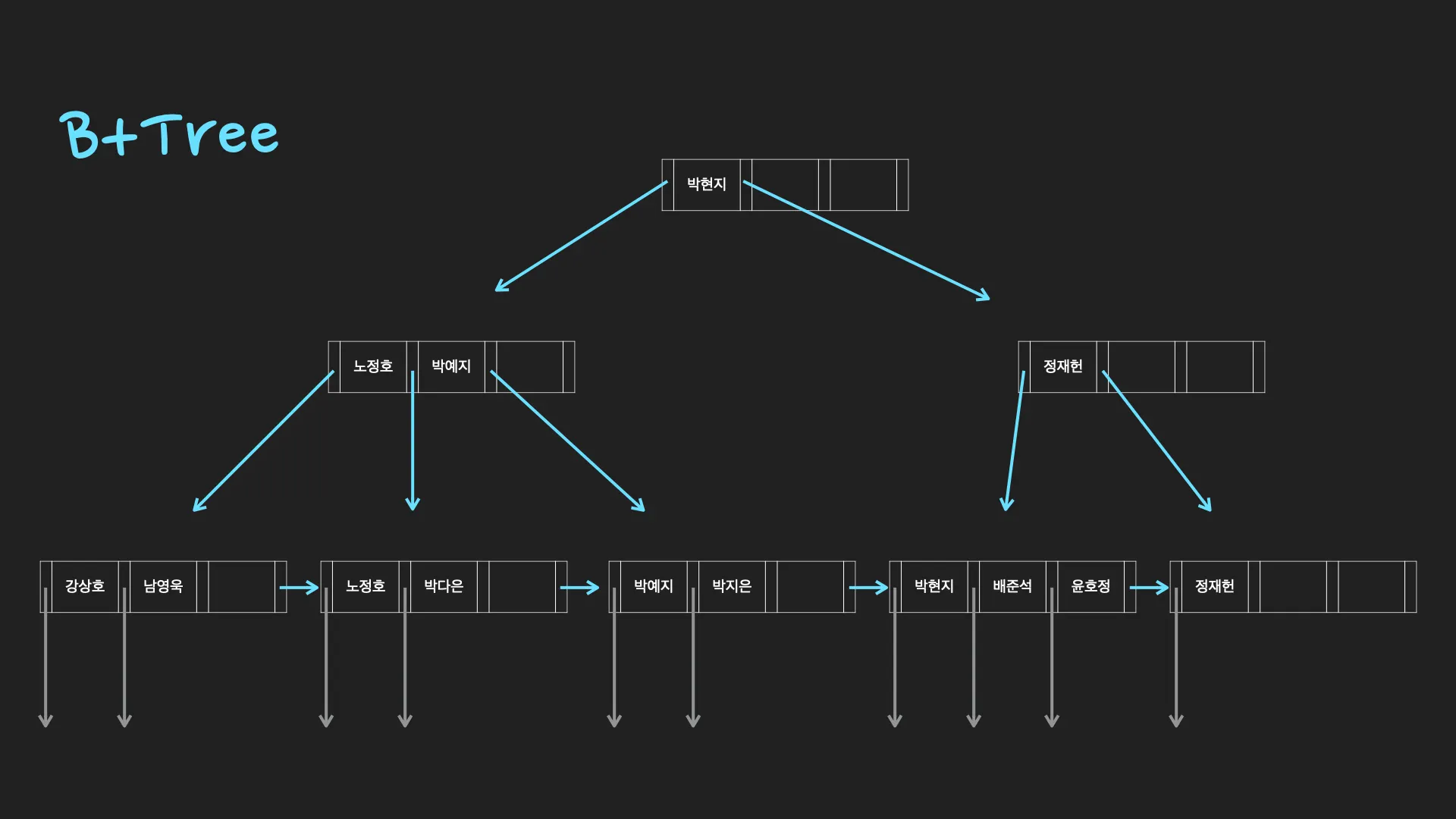
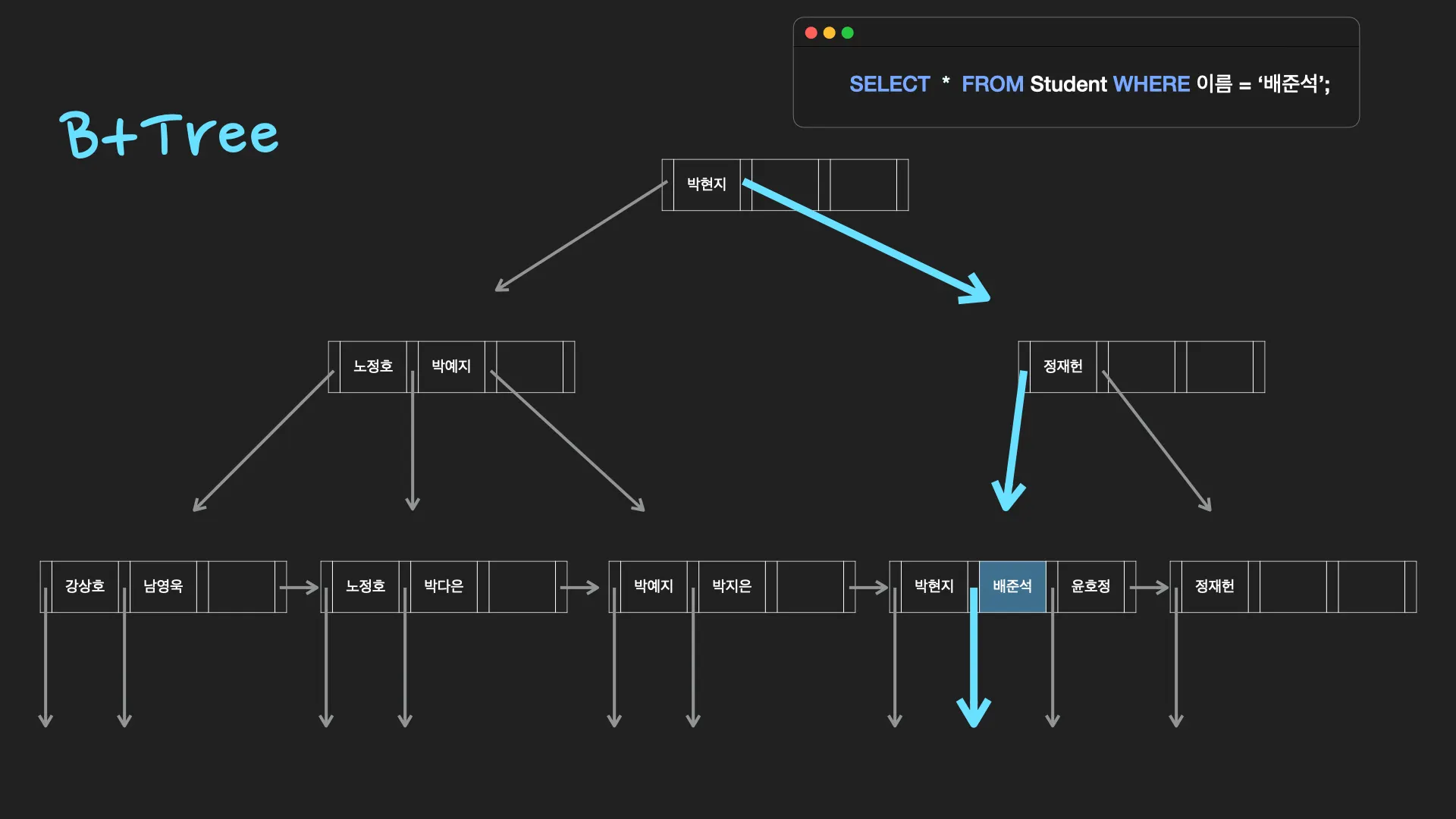
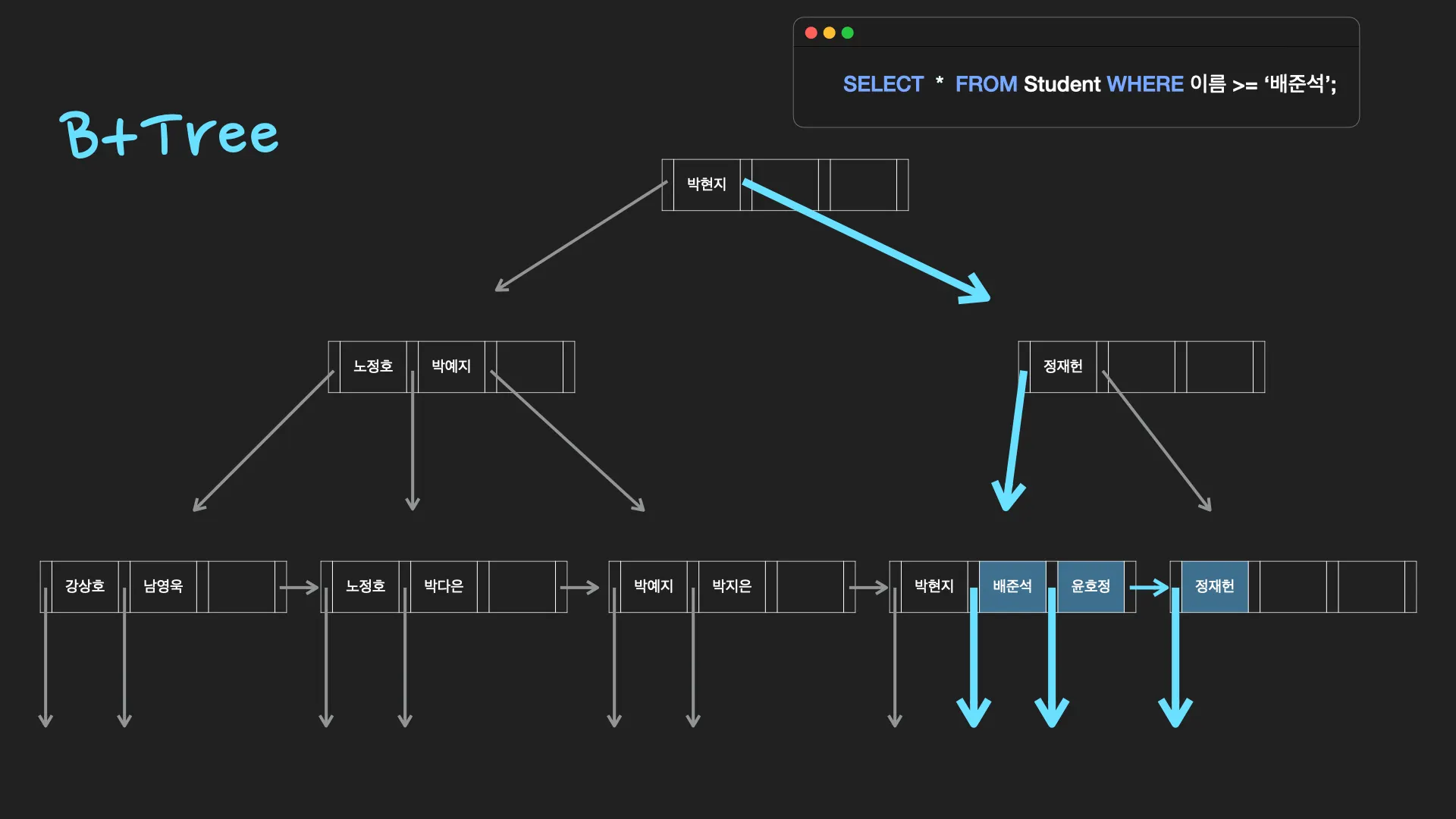
B+tree
[B+tree가 DB index를 위한 자료구조로 적합한 이유]
1.
항상 정렬된 상태를 유지하여 부등호 연산에 유리합니다.
2.
데이터 탐색뿐 아니라, 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도를 갖습니다.
Hash index
hash index는 빠른 데이터 검색이 필요할 때 유용합니다. 하지만 index로써 hash index가 사용되는 경우는 제한적입니다. 왜냐하면 hash index는 등호(=) 연산에만 특화되었기 때문입니다. 데이터가 조금이라도 달라지면 hash funcdtion은 완전히 다른 hash 값을 생성하는데, 이러한 특성 때문에 부등호 연산(>, <)이 자주 사용되는 DB 검색에는 hash index가 적합하지 않습니다.