
[핵심 답변]
Index는 데이터베이스에서 table의 검색 성능을 높여주는 대표적인 방법중 하나입니다. 일반적인 RDBMS(관계형데이터베이스)에서는 B+Tree구조로 된 index를 사용하여 검색속도를 향상시킵니다.
index는 책마다 마지막 페이지에 있는 색인(index)과 같은 역할을 하는 자료구조입니다. 책에서 어떤 용어나 단어를 찾기위해 첫 페이지부터 끝 페이지 까지 전체를 훑지 않아도(Full Table Scan) index를 찾아보면 몇 페이지에 적혀 있는지 바로 찾을 수 있는 것(Index Scan)과 비슷합니다.
SELECT ~WHERE query를 통해 특정 조건을 만족하는 데이터를 찾을 때, full table scan할 필요 없이 정렬되어 있는 index에서 훨씬 빠른 속도로 검색을 할 수 있게 됩니다.
[면접  TIP]
TIP]
TIP]Index는 개발자 면접 질문중에 가장 중요하고 자주 나오는 내용중에 하나 입니다. Index가 왜 필요하고 어느 상황에서 필요한지 묻는 질문을 받았을 때 index의 구조와 장단점을 알면 대답을 하기 수월합니다. 따라서 index의 원리와 어떤 역할을 하는지, 그리고 장단점과 구조는 어떻게 되는지에 초점을 맞춰서 학습해보도록 하겠습니다.
Index 구조
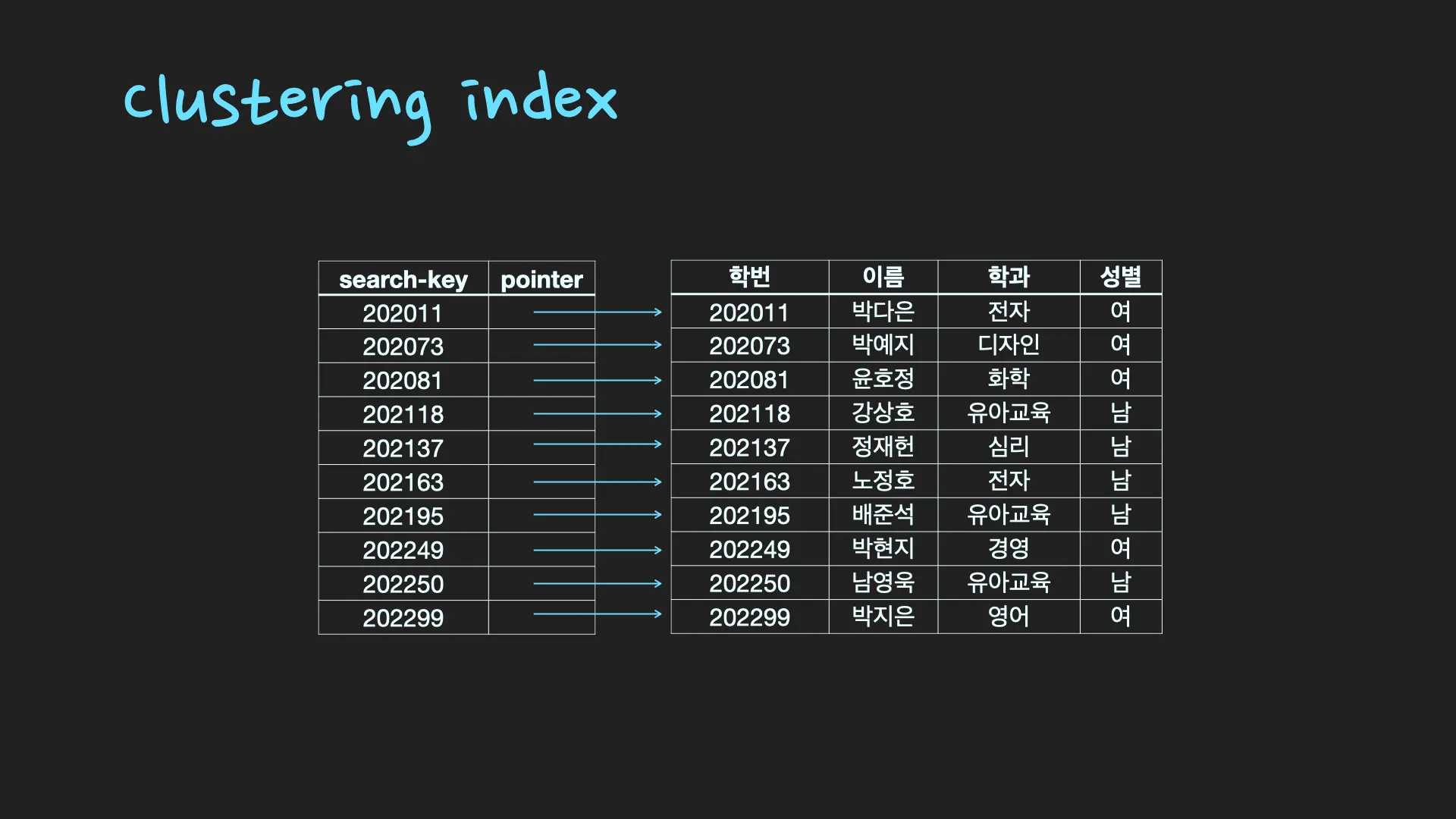
Index는 Btree, B+tree, Hash, Bitmap로 구현될 수 있습니다. 많은 데이터베이스 시스템에서 index는 B+tree구조를 가집니다. index를 생성하게 되면 특정 column(속성, attribute)의 값을 기준으로 정렬하여 데이터의 물리적 위치와 함께 별도 파일에 저장합니다. 이 때, Index에 저장되는 속성 값을 search-key값이라고 하고 실제 데이터의 물리적 위치를 저장한 값을 pointer라고 합니다. 즉, index는 순서대로 정렬된 search-key값과 pointer값만 저장하기 때문에 table보다 적은 공간을 차지합니다.
정리해보면 특정 column을 search-key 값으로 설정하여 index를 생성하면, 해당 search-key 값을 기준으로 정렬하여 (search-key, pointer)를 별도 파일에 저장합니다. 이를 index라고 합니다.
Index 사용하는 이유
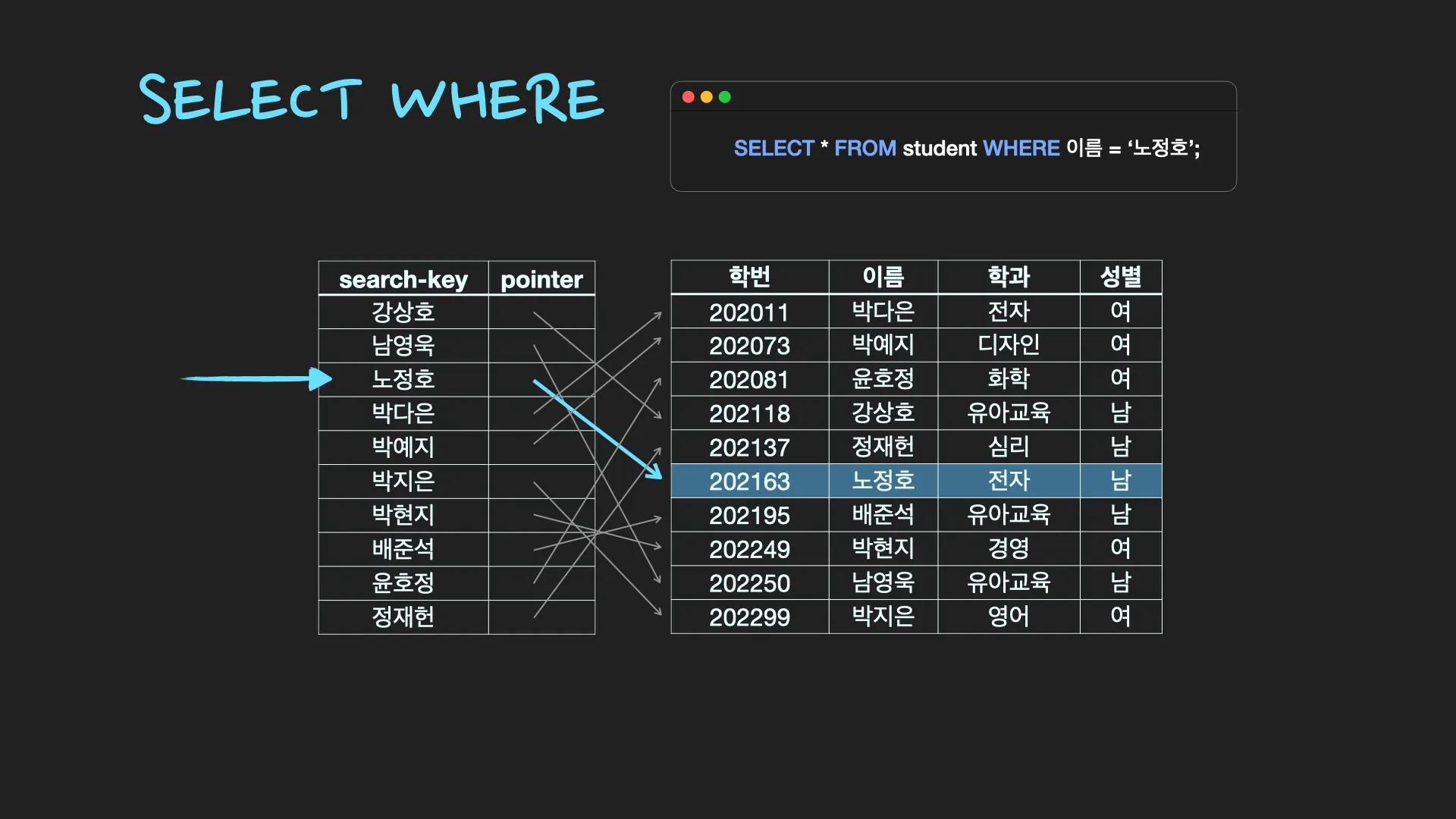
Table에 데이터를 지속적으로 저장하게 되면 내부적으로 순서 없이 쌓이게 됩니다. 이 경우에 특정 조건을 만족하는 데이터를 찾고자 WHERE절을 사용한다면 Table의 row(record)를 처음부터 끝까지 모두 접근하여 검색조건과 일치하는지 비교하는 과정이 필요합니다. 이를 Full Table Scan이라고 합니다. 하지만 특정 coloumn에 대한 Index를 생성해 놓은 경우 해당 속성에 대하여 search-key가 정렬되어 저장되어 있기 때문에 조건 검색(SELECT ~ WHERE) 속도가 굉장히 빠릅니다.
클러스터형 인덱스와 보조 인덱스(clustering index & secondary index)
•
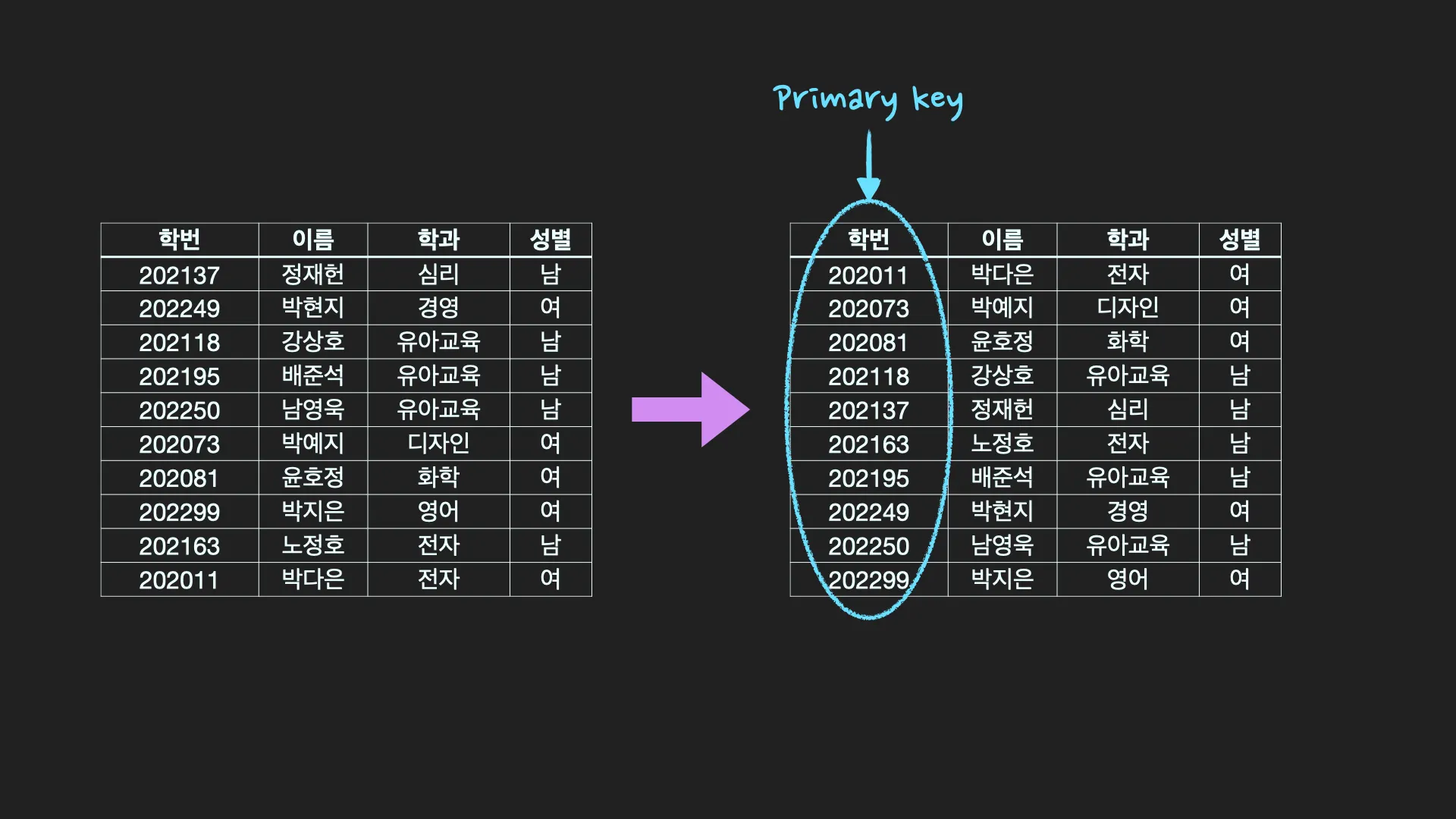
clustering index: 특정 column을 기본키(primary key)로 지정하면 자동으로 클러스터형 인덱스가 생성되고, 해당 column 기준으로 정렬이 됩니다. Table 자체가 정렬된 하나의 index인 것입니다. 마치 영어사전처럼 책의 내용 자체가 정렬된 것을 떠올리면 쉽습니다.
•
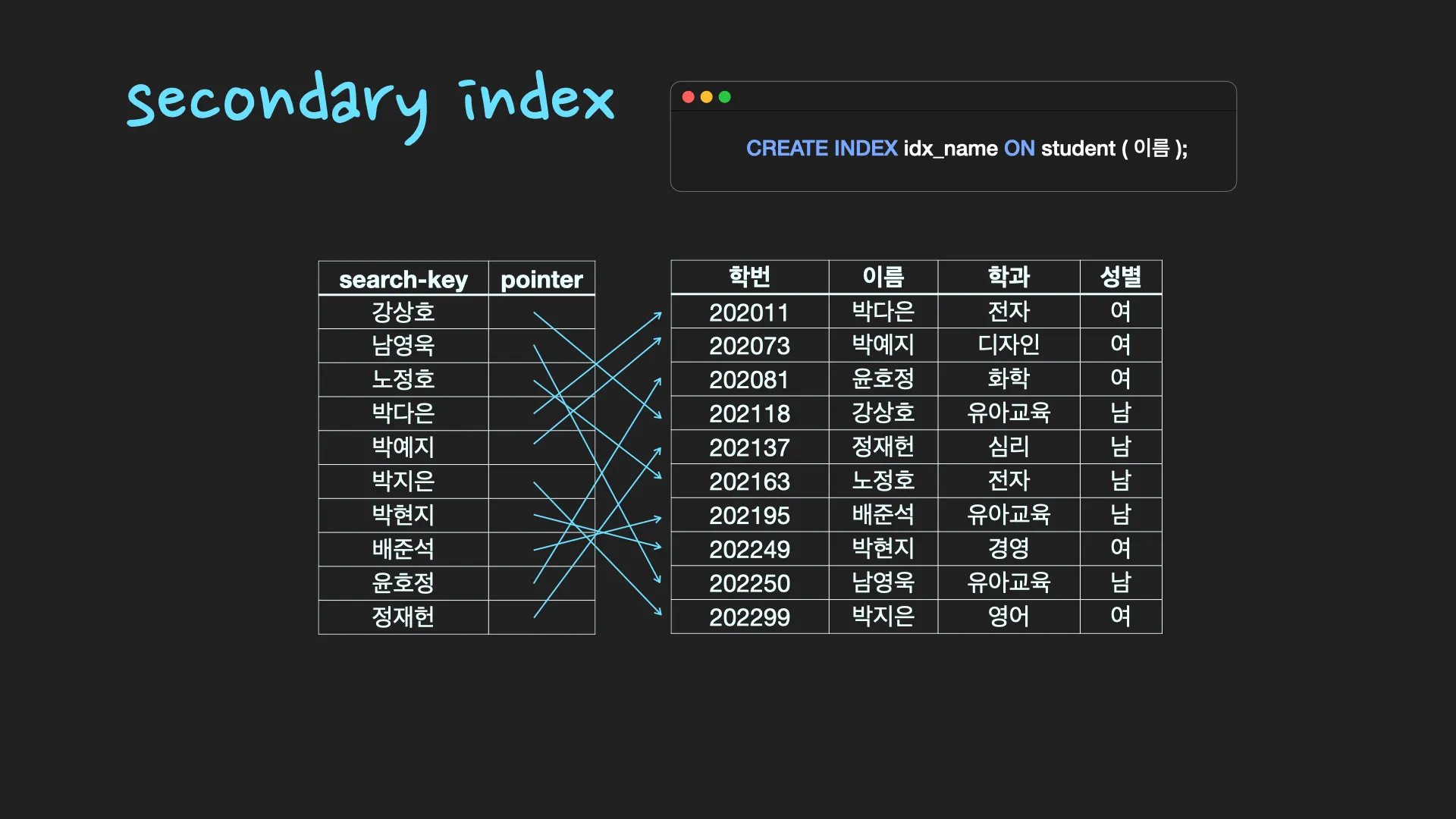
secondary index : 일반 책의 찾아보기와 같이 별도의 공간에 인덱스가 생성됩니다. create index와 같이 index를 생성하기를 하거나 고유키(unique key)로 지정하면 보조 인덱스가 생성됩니다.
Index의 장단점
Index의 최대 장점은 검색 속도 향상 (SELECT~WHERE~ ) 입니다. 테이블을 만들고 안에 데이터가 쌓이게 되면 테이블의 record는 내부적으로 순서가 없이 뒤죽박죽으로 저장됩니다. 이렇게 되면 WHERE절을 통해 특정 조건에 맞는 데이터들을 찾아낼 때에도 reocrd의 처음부터 끝까지 다 읽어서 검색 조건과 맞는지 비교해야 합니다. 이것을 Full Table Scan이라고 합니다. 반면에 index를 생성하면 index에는 데이터들이 정렬되어 저장되어 있기 때문에 검색 조건에 일치하는 데이터들을 빠르게 찾아낼 수 있습니다. 이것이 Index를 사용하는 가장 큰 이유입니다.
Index의 단점으로는 크게 두 가지가 있습니다.
1.
추가 저장공간 필요
index를 생성하면 index 자료구조를 위한 저장 공간이 추가적으로 필요합니다. 보통 table의 크기의 10%정도의 공간을 차지합니다.
2.
느린 데이터 변경 작업
검색이 아닌 데이터 변경을 할 때, 즉 INSERT, UPDATE, DELETE가 자주 발생하면 성능이 나빠질 수 있습니다. 그 이유는 보통 B+tree구조의 index는 데이터가 추가 삭제 될 때마다 tree의 구조가 변경될 수 있기 때문입니다. 즉 인덱스의 재구성이 필요하기 때문에 추가적인 자원이 소모됩니다.
[꼬꼬무 문답]
Q. SELECT의 성능을 높일 수 있는 방법엔 무엇이 있을까요?
Q. index의 내부 동작은 어떻게 되나요?
Q. index를 많이 생성하면 안 되나요?