
해시테이블 (Hash Table)

Hash table은 효율적인 탐색(빠른 탐색)을 위한 자료구조로써 key-value쌍의 데이터를 입력받습니다. hash function 에 key값을 입력으로 넣어 얻은 해시값 를 위치로 지정하여 key- value 데이터 쌍을 저장합니다. 저장, 삭제, 검색의 시간복잡도는 모두 입니다.
Direct-address Table
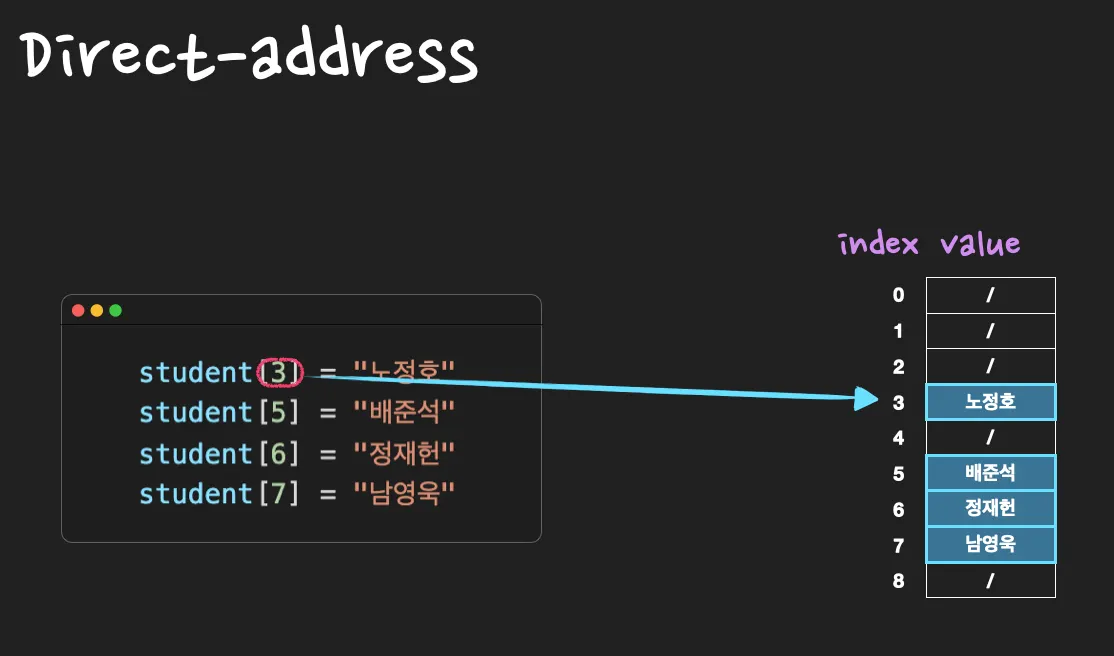
Direct-address Table(직접 주소화 테이블)이란, key값이 인 데이터를 index 위치에 저장하는 방식입니다.
key: 출석번호, value: 이름
(3, 노정호)
(5, 배준석)
(6, 정재헌)
(7, 남영욱)
Plain Text
복사
직접 주소화 방법으로 통해 key-value 쌍의 데이터를 저장하고자 하면 많은 문제가 발생합니다.
문제점 1) 불필요한 공간 낭비
key: 학번, value: 이름
(2022390, 노정호)
(2022392, 배준석)
(2022393, 정재헌)
(2022401, 남영욱)
Plain Text
복사

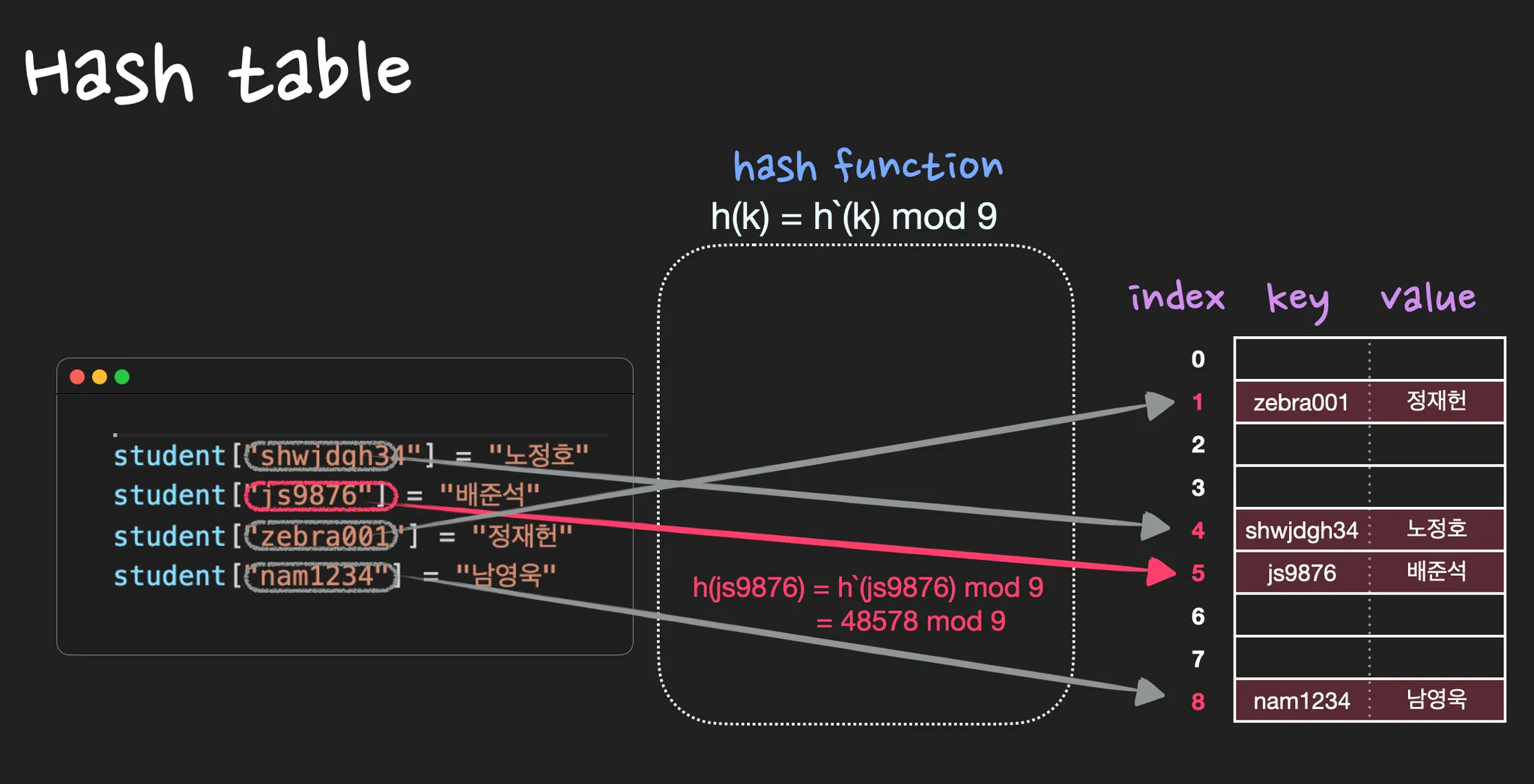
문제점 2) Key값으로 문자열이 올 수 없다.
key: ID, value: 이름
(nossi8128, 노정호)
(js9876, 배준석)
(zebra001, 정재헌)
(nam1234, 남영욱)
Plain Text
복사

Hash table
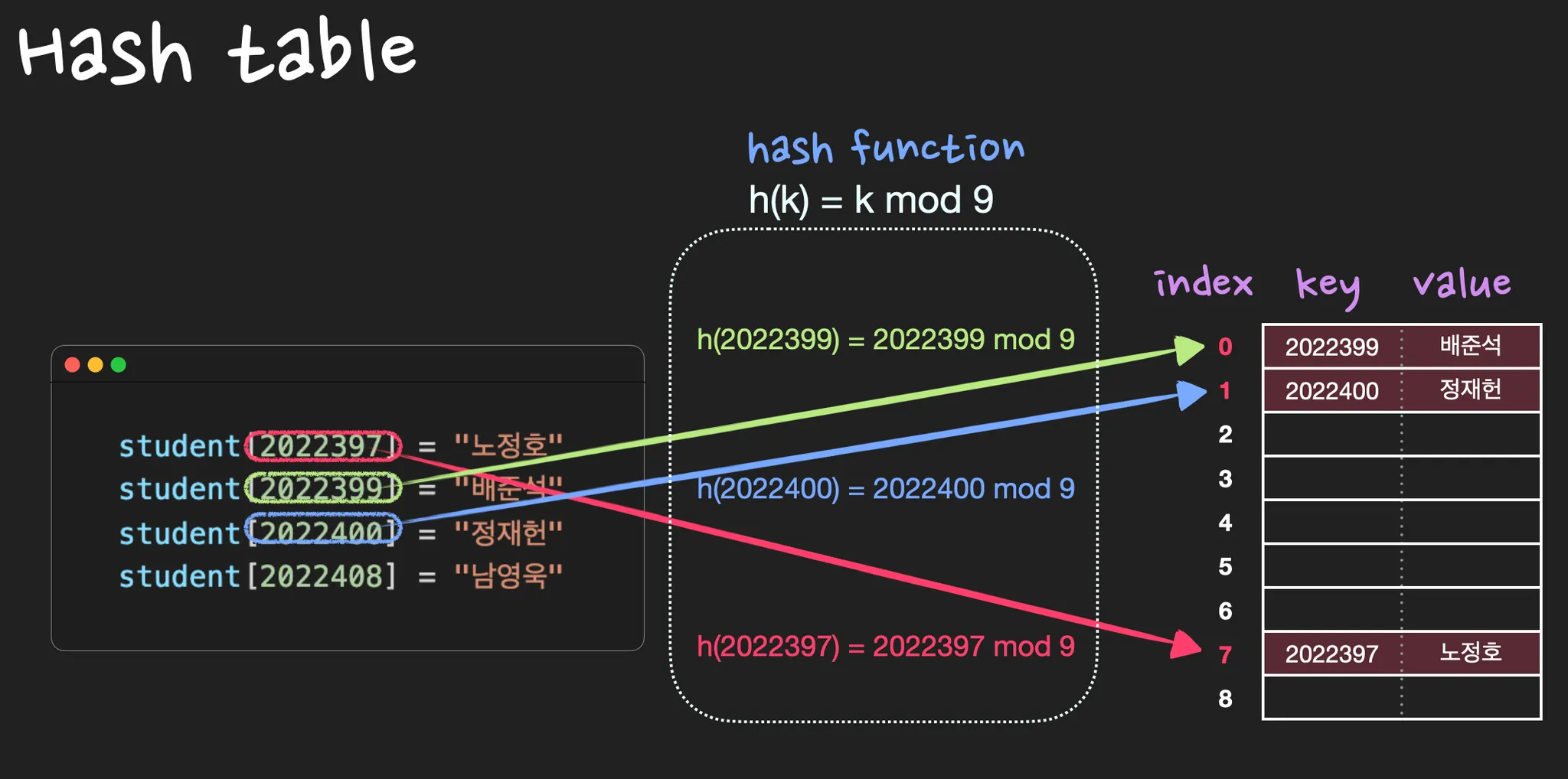
위와 같은 이유로, 직접 주소화 방법은 (key, value) 데이터 쌍을 저장하기 위한 방법으로 잘 맞지않습니다. 그 대안으로, 우리는 Hash table을 이용할 것입니다. Hash table은 hash function 를 활용해서 (key, value)를 저장합니다. key값을 라고 했을 때, 함수값에 해당하는 index에 (key, value) 데이터 쌍을 저장합니다.
“는 키 의 해시값이다” 라고 표현합니다.
모든 데이터에 key값은 무조건 존재해야 하며, 중복되는 key값이 있어서는 안됩니다.
한편, (key, value) 데이터를 저장할 수 있는 각각의 공간을 slot 또는 bucket이라고 합니다.
Collision
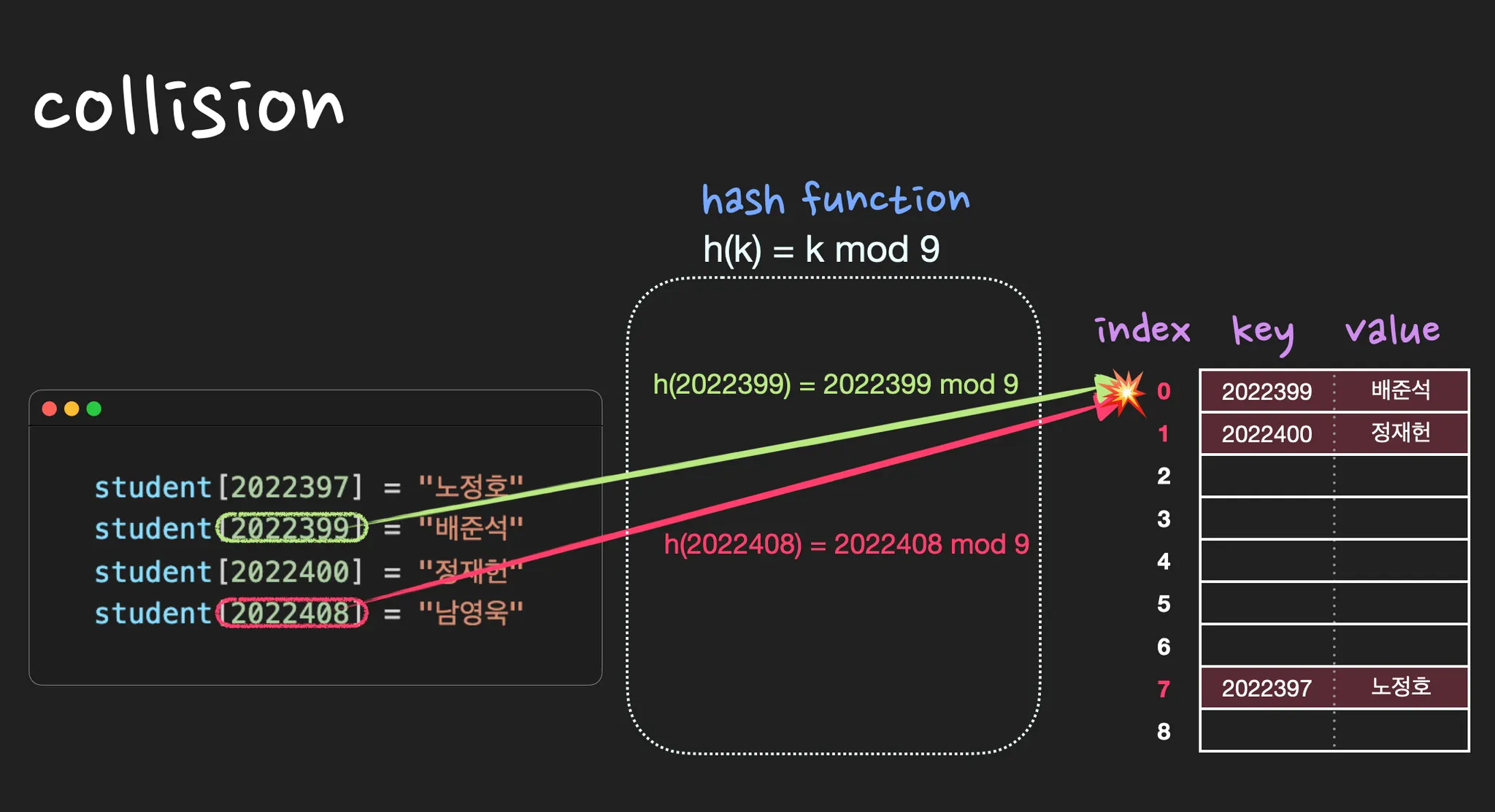
collision이란 서로 다른 key의 해시값이 똑같을 때를 말합니다. 즉, 중복되는 key는 없지만 해시값은 중복될 수 있는데 이 때 collision이 발생했다고 합니다. 따라서 collision이 최대한 적게 나도록 hash function을 잘 설계해야하고, 어쩔 수 없이 collision이 발생하는 경우 seperate chaining 또는 open addressing등의 방법을 사용하여 해결합니다.
시간복잡도와 공간효율
시간복잡도는 저장, 삭제, 검색 모두 기본적으로 입니다. 다만 collision으로 인하여 worst case 이 될 수 있습니다.
공간효율성은 떨어집니다. 데이터가 저장되기 전에 미리 저장공간(slot, bucket)을 확보해야 하기 때문입니다. 따라서 저장공간이 부족하거나 채워지지 않은 부분이 많은 경우가 생길 수 있습니다.
Hash table | Linked list | Array | |
access | |||
insert | |||
append | |||
delete |
해시테이블 사용법 - dictionary
파이썬의 딕셔너리는 hash table로 구현되어 있습니다.
hashtable = {}
Python
복사
hash table은 앞서 key-value의 쌍으로 이루어졌다고 했습니다. 파이썬에서는 key를 리스트의 index처럼 생각하면 편합니다.
예를 들어 리스트에서 value를 access하거나 update 할 때, index를 사용했습니다.
a = [1, 3, 5, 7]
a[3] # 5
a[3] = 0
Python
복사
dictionary도 마찬가지입니다. 아래와 같이 key-value가 있을 때, key를 index처럼 생각해주는 것입니다.
key: 학번, value: 이름
(2022390, 노정호)
(2022392, 배준석)
(2022393, 정재헌)
(2022401, 남영욱)
Plain Text
복사
student_info = {}
student_info[2022390] = "노정호"
student_info[2022392] = "배준석"
student_info[2022393] = "정재헌"
student_info[2022401] = "남영욱"
Python
복사
in 연산자
dictionary는 in 연산자와 결합했을 때 강력한 힘을 발휘합니다. in은 dictionary에서 key가 존재하는 지 확인 해줍니다.
만약 key가 존재하면 True를 반환하고 존재하지 않으면 False를 반환합니다.
if 2022390 in student_info:
print("학생이 존재합니다")
else:
print("학생이 존재하지 않습니다")
Python
복사
그리고 이 in 연산자의 시간복잡도는 으로 매우 효율적입니다.
list도 in 연산자를 사용하여, value가 있는지 없는지 확인할 수 있지만, 의 시간복잡도를 가집니다.
Dictionary 관한 함수
1. dictionary.items()
key와 value 모두 접근할 때 사용합니다.
for student_id, name in student_info.items():
print(student_id, name)
Python
복사
결과
2. dictionary.keys()
dictionary의 key들을 접근할 때 사용합니다.
for student_id in student_info.keys():
print(student_id)
Python
복사
결과
3. dictionary.values()
dictionary의 value들을 접근할 때 사용합니다.
for name in student_info.values():
print(name)
Python
복사
결과
4. dictionary.get()
key에 해당하는 value을 가져올 때 사용됩니다.
print(student_info.get(2022390))
Python
복사
결과
만약 다음과 같이 없는 값을 가져오면 어떻게 될까요?
print(student_info.get(1111))
Python
복사
결과
이렇게 없는 값을 가져올 경우, default를 지정할 수도 있습니다.
print(student_info.get(1111, "김기영"))
Python
복사
결과
조금 더 응용하면, 매우 편리하게 사용할 수 있습니다.
if 3 not in a:
a[3] = 1
else:
a[3] += 1
Python
복사
위와 같은 코드를 단 1줄만으로 작성할 수 있게 됩니다.
a[3] = 1 + a.get(3, 0)
Python
복사
그럼 딕셔너리가 만능일까요?
지금까지만 보면 딕셔너리는 list의 완벽한 상위호환 같습니다. 그러나 list도 list의 장점이 있습니다. 그것은 순서가 있다는 것입니다. 그렇기에 list와 다르게 dictionary를 정렬할 수 없습니다.
sorted_dict = sorted(my_dict.items())
Python
복사
다음과 같이 정렬한다 하더라도, 결국에는 list로 반환됩니다.
그렇기에 데이터의 순서가 중요할 때는 list를 사용하는 것이 바람직합니다.
Copyright. 노씨데브. All rights reserved. 무단 공유 및 배포를 금합니다.