
그래프 (Graph)
그래프의 정의

그래프(G)는 정점(vertex)들의 집합 V와 이들을 연결하는 간선(edge)들의 집합 E로 구성된 자료구조입니다.
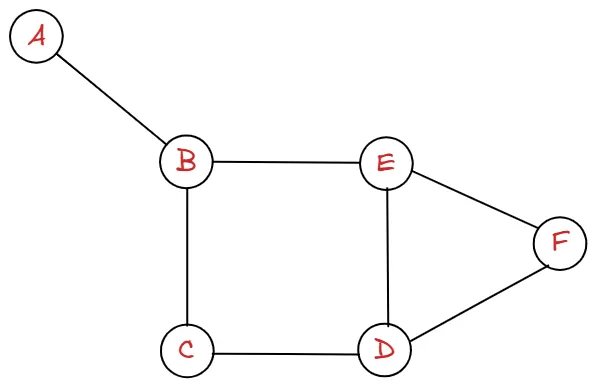
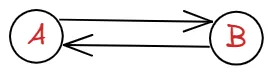
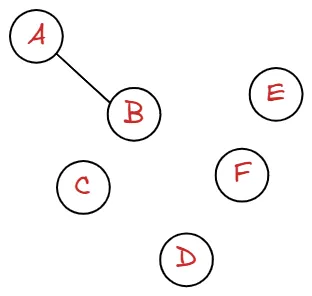
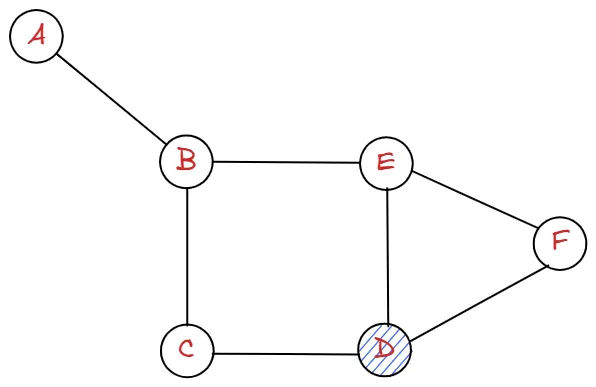
위와 같은 그래프가 있다고 할 때, 정점은 A, B, C, D, E, F 입니다.
또 정점들을 연결하는 간선들은 A-B, B-C, B-E, C-D, E-D, E-F, E-D 입니다.
즉 위의 그래프는 정점들의 집합 와 이들을 연결하는 간선들의 집합 로 이루어져 있습니다.
그래프의 활용
그래프는 이렇듯 연결 관계를 표현하기에 현실 세계의 사물이나 추상적인 개념들을 잘 표현 할 수 있습니다.
•
도시들을 연결하는 도로망: 도시(vertex), 도로망(edge)
•
지하철 연결 노선도: 정거장(vertex), 정거장을 연결한 선(edge)
•
컴퓨터 네트워크: 각 컴퓨터와 라우터(vertex), 라우터간의 연결 관계(edge)
•
소셜 네트워크 분석: 페이스북의 계정(vertex), follow 관계(edge)
그래프의 종류
위와 같은 기본적인 그래프에서 시작하여, 다양한 그래프를 살펴 볼 수 있습니다.
1. 무향 그래프(undirected graph) vs 방향 그래프(directed graph)
앞서서 다룬 그래프를 다시 살펴보도록 합시다.
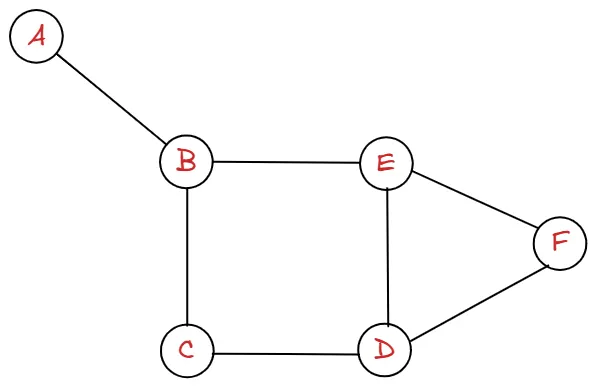
위와 같은 그래프는 A→B로 갈 수 있으며, B→A로도 갈 수 있기에 무향 그래프(undirected graph)라고 합니다. 따로 방향이 안 정해져 있기 때문입니다.
한편 다음과 같이 간선의 방향이 정해져 있는 그래프도 있습니다.
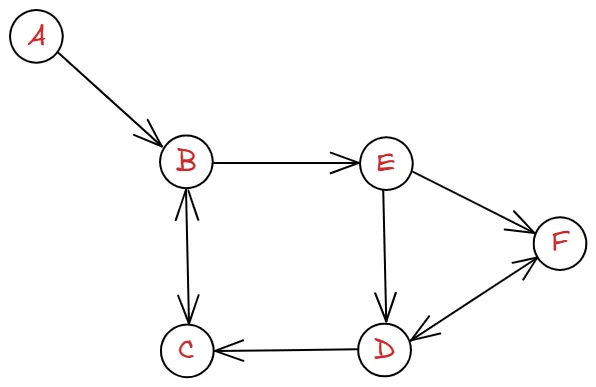
위와 같이 방향이 정해져 있는 그래프를 방향 그래프(directed graph)라 합니다.
그래프를 잘 살펴보면 들어오는 간선과 나가는 간선으로 구분할 수 있습니다.. 이 때 들어오는 간선을 indegree라 하며, 나가는 간선을 outdegree라 합니다. 정점 B를 살펴보면 A와 C로부터 들어오는 indegree 2개, E로 나가는 outdegree 1개가 있는 것을 알 수 있습니다.
코딩테스트에서는 주로 무향 그래프(undirected graph)를 다룹니다.
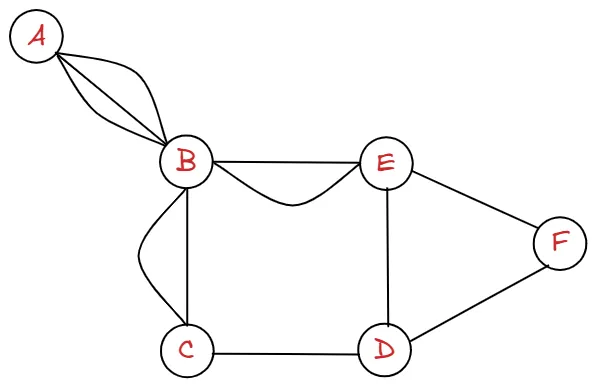
2. 다중 그래프 vs 단순 그래프
다시 그래프를 보도록 하겠습니다.
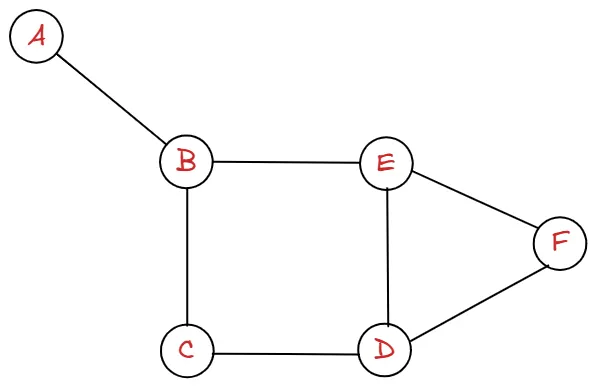
인접해 있는 두 정점과의 관계를 살펴보도록 합시다. 등이 있을 것입니다. 이 때 두 정점 사이에 indegree가 1개, outdegree가 1개인 그래프를 simple graph 라고 합니다.
하지만 다음과 같이 여러 길이 존재 할 수 도 있습니다.
A에서 B까지 가는 방법이 총 3개 있습니다. 다시 말해 인접해 있는 두 정점 A,B 사이에 A를 기준으로 ingree가 3개 outdegree가 3개가 있습니다.
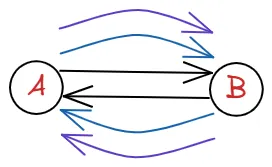
이렇게 인접해 있는 두 정점 A,B의 관계에서 outdegree와 indegree가 2개 이상인 그래프를 다중그래프라고 합니다.
코딩 테스트에서는 주로 단순 그래프(simple graph)를 다룹니다.
3. 가중치 그래프
다시 그래프를 보도록 하겠습니다.
현재 이 그래프에서는 A에서 B로 , B에서 E로 등 모든 경로의 비용(시간)이 동일하다고 가정했습니다. 하지만, 아래와 같이 경로마다 비용을 다르게 설정할 수 있습니다. 각 경로 마다 가중치가 다르다 하여 아래와 같은 그래프를 가중치 그래프라고 정의합니다.
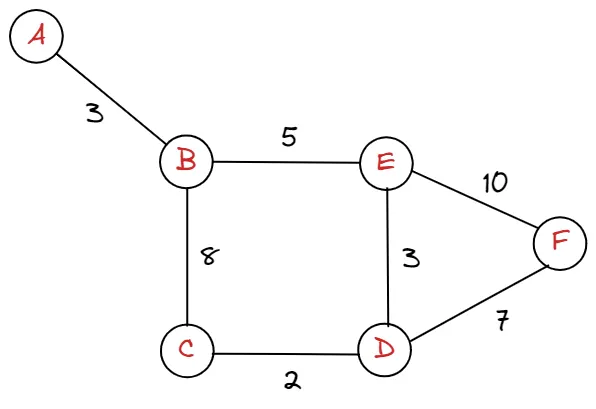
가중치 그래프는 추후 다익스트라 알고리즘에서 쓰입니다. 코딩테스트 입문편에서는 가중치 그래프를 다루지 않으며, 심화편에서 다루도록 하겠습니다.
그래프의 구현
여러가지 그래프를 보았으니, 이제 그래프를 구현하도록 하는 시간을 갖겠습니다. 그래프를 구현 하는 방법으로는 총 3가지가 있습니다.
1.
인접 행렬
2.
인접 리스트
3.
암시적 그래프
각 그래프를 구현 하는 방법을 알아보도록 하겠습니다.
1. 인접 행렬
행렬은 행(row)과 열(column)에 따라, 정보들을 직사각형 모양으로 배열한 것입니다.
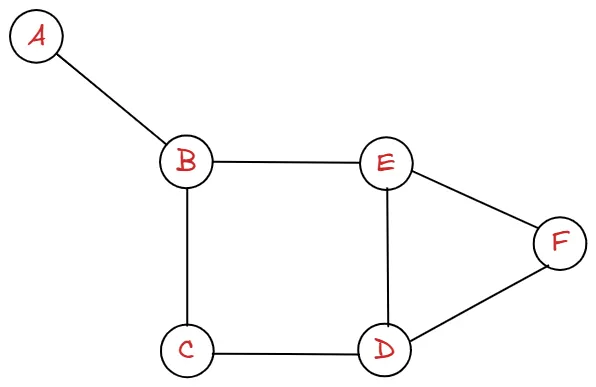
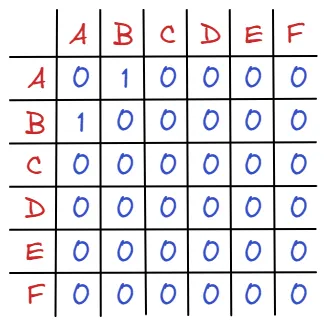
다음 그래프가 있을 때, 각 정점들을 하나의 행(가로)과 열(세로)이라 생각할 수 있습니다.
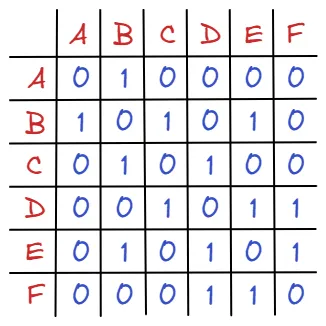
와 같이 말이죠. 그 후 그래프의 연결 관계를 생각해볼 수 있습니다. 정점끼리 연결 되어 있으면 1 ,연결되어 있지 않으면 0을 대입해보도록 합시다.
흔히 행렬을 만들기 위해서는 이중리스트를 사용합니다.
위와 같은 matrix가 있을 때 코드로 표현하면 다음과 같습니다.
matrix = [[1, 2, 3], [4, 5, 6]]
Python
복사
인접행렬 역시 마찬가지 입니다. 다만, 리스트에서 A,B ... index는 존재 하지 않기에 A를 0 index, B를 1 index와 같이 생각해줍니다.
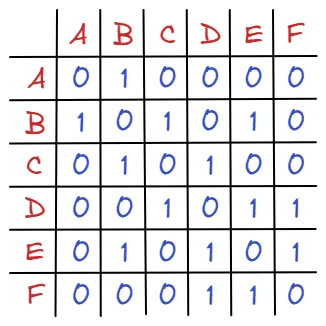
matrix = [
[0, 1, 0, 0, 0, 0],
[1, 0, 1, 0, 1, 0],
[0, 1, 0, 1, 0, 0],
[0, 0, 1, 0, 1, 1],
[0, 1, 0, 1, 0, 1],
[0, 0, 0, 1, 1, 0],
]
Python
복사
위 그래프에서 특징적인 점은 자기 자신(ex A-A, B-B)을 연결하는 간선이 없기 때문에, 대각선의 값이 모두 0이라는 점과 무향 그래프 이기 때문에 대각선을 기준으로 대칭입니다.
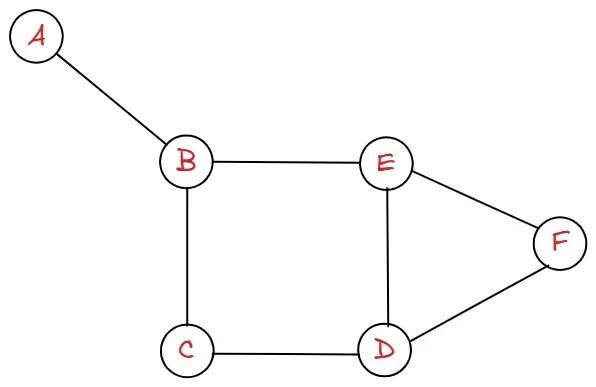
이제 저희는 모든 그래프에 대해서 인접 행렬을 그릴 수 있습니다. 하지만 인접 행렬이 만사는 아닙니다. 다음과 같이 정점은 엄청 많은데, 간선의 개수가 적을 때는 비효율적입니다.
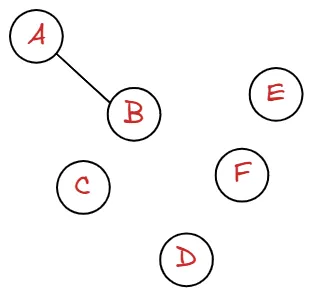
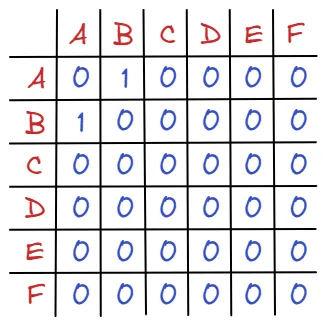
다음과 같이 A-B의 관계를 제외하고는 모두 0으로 나타내기 때문에, 메모리 사용 측면에서 비효율적이라고 할 수 있습니다. 그래프는 연결 관계를 나타내는 것이 중요한데, 0은 정보로서 가치가 떨어집니다.
인접 리스트를 사용하면, 위와 같은 문제를 해결 할 수 있습니다.
2. 인접 리스트
인접 리스트는 딕셔너리 {}의 형태로 정의됩니다. 딕셔너리는 key와 value로 정의되는 자료구조였었죠. 인접 리스트 같은 경우, key에는 정점들이 들어가며, value에는 list 형태로 연결 관계를 표시해줍니다.
실제 예시를 봐보도록 합시다.
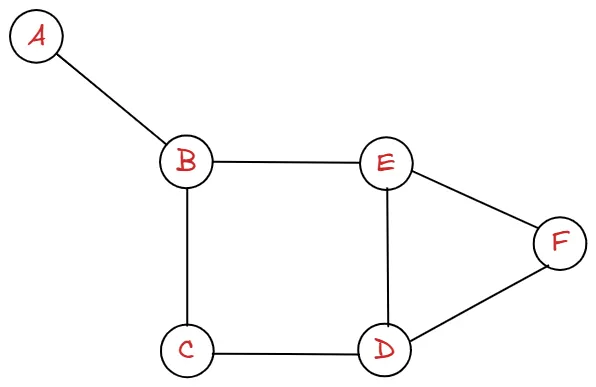
graph = {
"A": ["B"],
"B": ["A", "C", "E"],
"C": ["B", "D"],
"D": ["C", "E", "F"],
"E": ["B", "D", "F"],
"F": ["D", "E"],
}
Python
복사
위에서 인접 리스트 같은 경우, 정점들이 많고, 간선이 적은 경우 대부분의 정보가 0으로 채워지기 때문에 비효율적이라고 하였습니다.
하지만 인접 리스트를 사용하게 되면, 이를 간편하게 표현 할 수 있습니다.
graph = {
"A": ["B"],
"B": ["A"],
"C": [],
"D": [],
"E": [],
"F": [],
}
Python
복사
코딩 테스트에서는 주로, 인접 행렬보다는 인접리스트를 사용합니다!
3. 암시적 그래프
코딩 테스트에서 제일 많이 활용되는 암시적 그래프를 다루어 보도록 하겠습니다. 그래프 문제를 풀다 보면 다음과 같은 문제들을 자주 접해 볼 수 있습니다.

다음과 같이 흰색이 길이고, 검은색이 벽인 미로가 있다고 합시다. 전혀 그래프 같지 않지만, 암시적으로 그래프처럼 표현 할 수 있습니다.

벽에는 1의 값을, 길에는 0의 값을 넣음으로써, 구분해보도록 합시다. 그리고 각 영역을 좌표의 개념을 도입하여 표현 할 수 있습니다.

graph = [
[1, 1, 1, 1, 1],
[0, 0, 0, 1, 1],
[1, 1, 0, 1, 1],
[1, 0, 0, 0, 0],
[1, 1, 1, 1, 1],
]
Python
복사
위의 표현 방식 같은 경우, 연결 관계를 직접적으로 나타내지는 않았습니다.
하지만 상하좌우가 연결되어 있다는 것을 암시적으로 알 수 있습니다.
예를 들어 (1,2)는 상(0,2), 하(2,2), 좌(1,1), 우(1,3)가 연결 되어있다는 것을 말이죠.
저희는 그래프의 값들을 row와 col이라는 변수명을 통해 값들을 접근할 것입니다.

가로를 row로 세로를 col로 생각하는 것 입니다. graph[row][col]를 통해 원하는 값을 접근할 수 있게 됩니다. 즉 (2,3)에 있는 값을 알고 싶으면, graph[2][3]을 통해 알 수 있습니다.
이제 그래프를 구현 할 수 있으니, 순회하는 방법을 알아보도록 합시다.
그래프의 순회
그래프의 순회는 트리의 순회와 마찬가지로, 모든 정점을 지나야 합니다. 대표적으로 2가지 방법이 있는데 BFS와 DFS입니다.
Breadth First Search
BFS 앞에서 배운 트리의 순회인 level order traversal과 매우 유사합니다. 그래프 순회를 할 때, 시작점이 주어질텐데, 이를 루트 노드라 생각하여, level 별로 탐색을 하는 것이 BFS입니다.
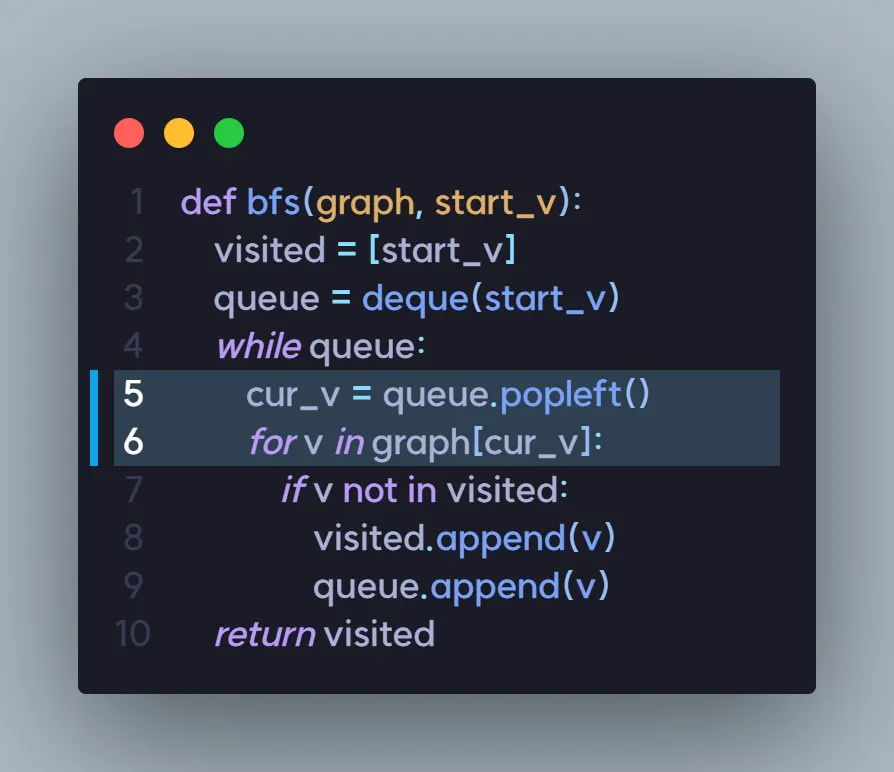
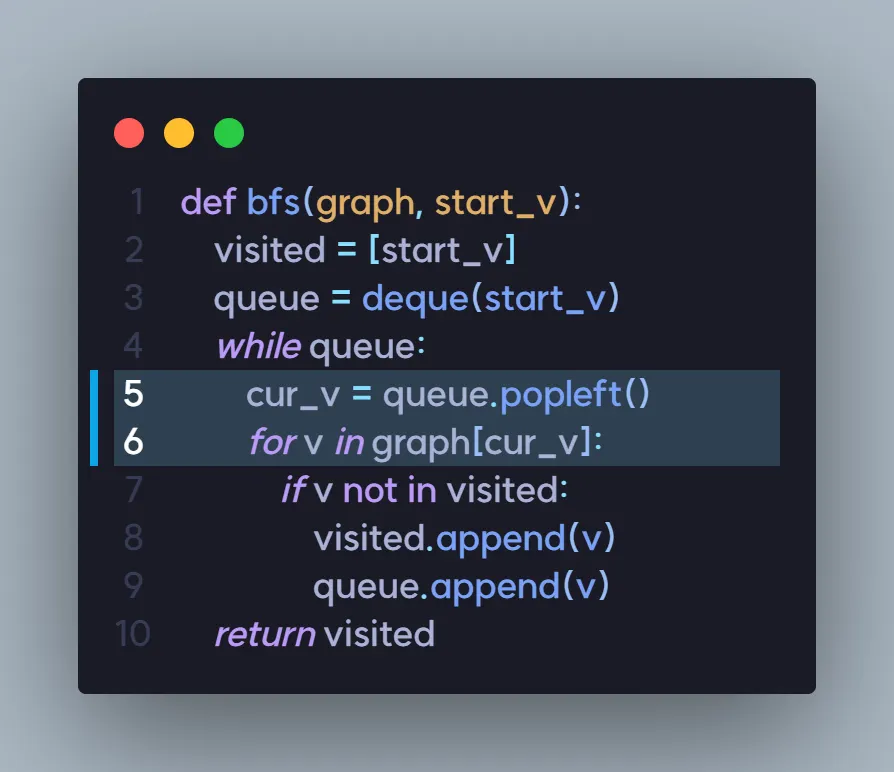
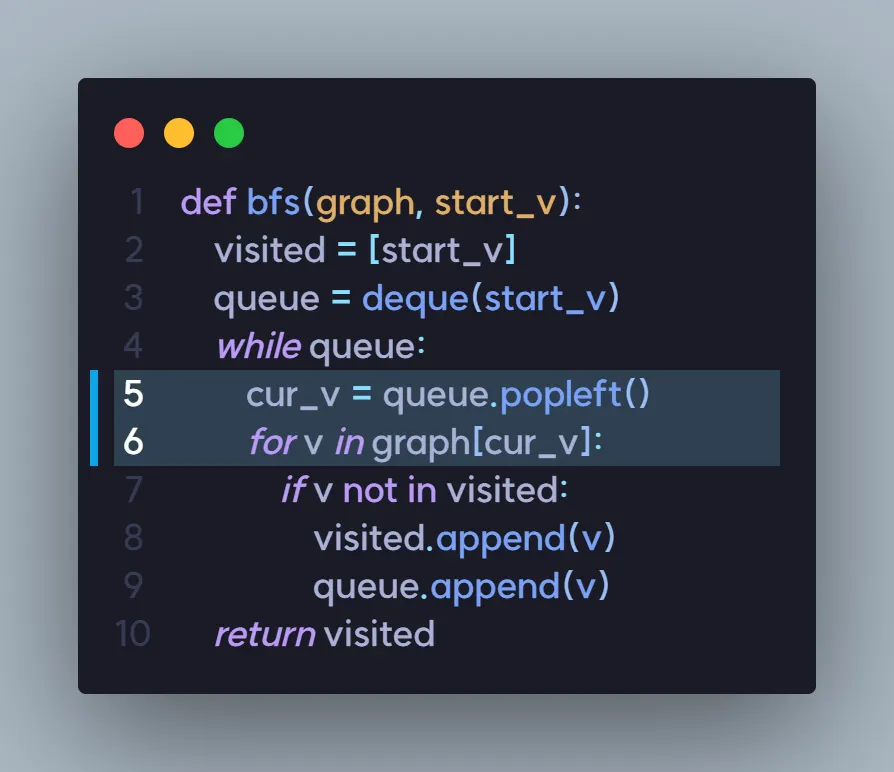
코드를 보면 진짜 다를 것이 없는 것을 알 수 있습니다.
from collections import deque
def bfs(graph, start_v):
visited = [start_v]
queue = deque(start_v)
while queue:
cur_v = queue.popleft()
for v in graph[cur_v]:
if v not in visited:
visited.append(v)
queue.append(v)
return visited
Python
복사
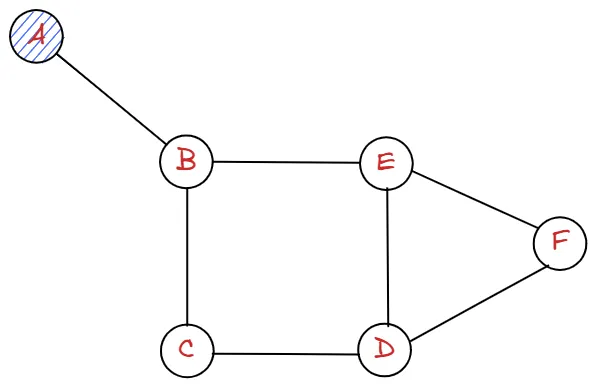
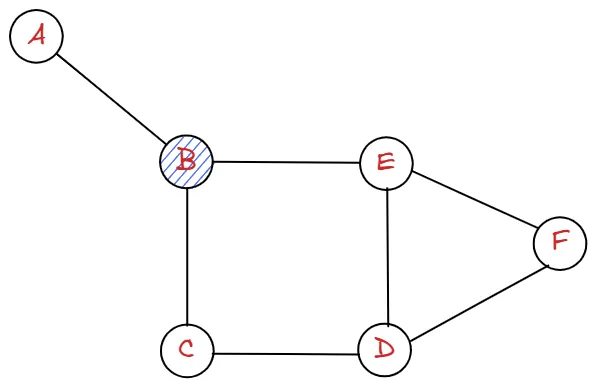
다음과 같은 그래프를 A에서 시작하여 탐색해보도록 하겠습니다.
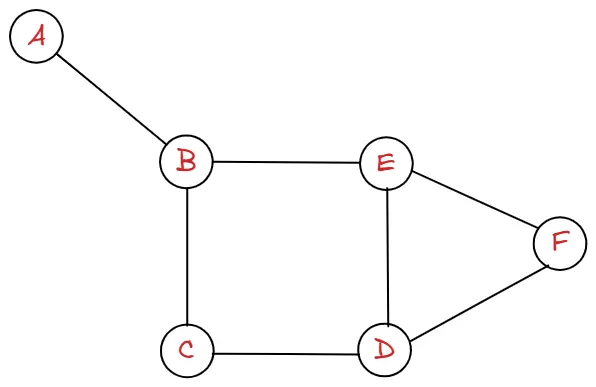
graph = {
"A": ["B"],
"B": ["A", "C", "E"],
"C": ["B", "D"],
"D": ["C", "E", "F"],
"E": ["B", "D", "F"],
"F": ["D", "E"],
}
Python
복사
시작점은 A라고 가정하겠습니다.
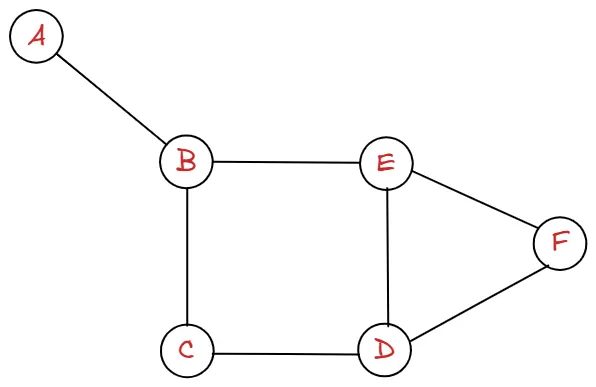

visited | A | ||||
queue | A |
시작하자마자 visited와 queue에 A가 들어갑니다.

visited | A | ||||
queue |
queue에서 A가 popleft된 후, graph["A"] 즉, ["B"]에 대해 반복문을 돌려 줘야합니다.
B는 visited에 없으므로, visited와 queue에 추가해줍니다.
visited | A | B | |||
queue | B |
queue가 비어있지 않으므로, while 반복문을 돌아야합니다.

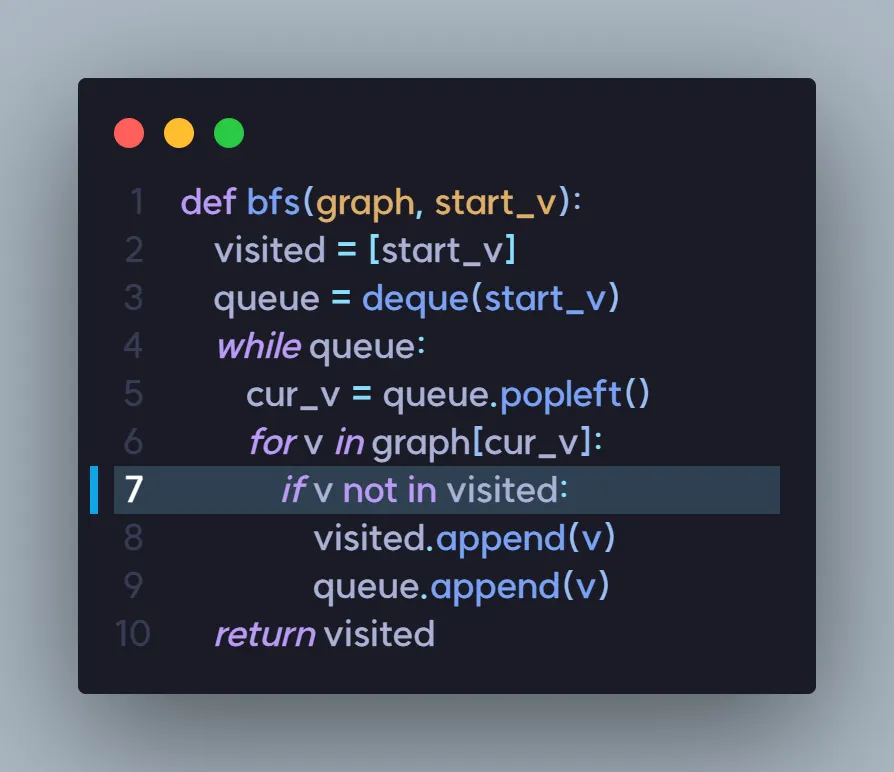
visited | A | B | |||
queue |
queue에서 B가 popleft된 후, graph["B"] 즉, ["A", "C", "E"]에 대해 반복문을 돌려 줘야합니다.
A는 visited에 있으므로 넘어 가줍니다.
C와 E는 visited에 없으므로, queue와 visited에 추가해 줍니다.
visited | A | B | C | E | |
queue | C | E |
queue가 비어있지 않으므로, while 반복문을 돌아야 합니다.
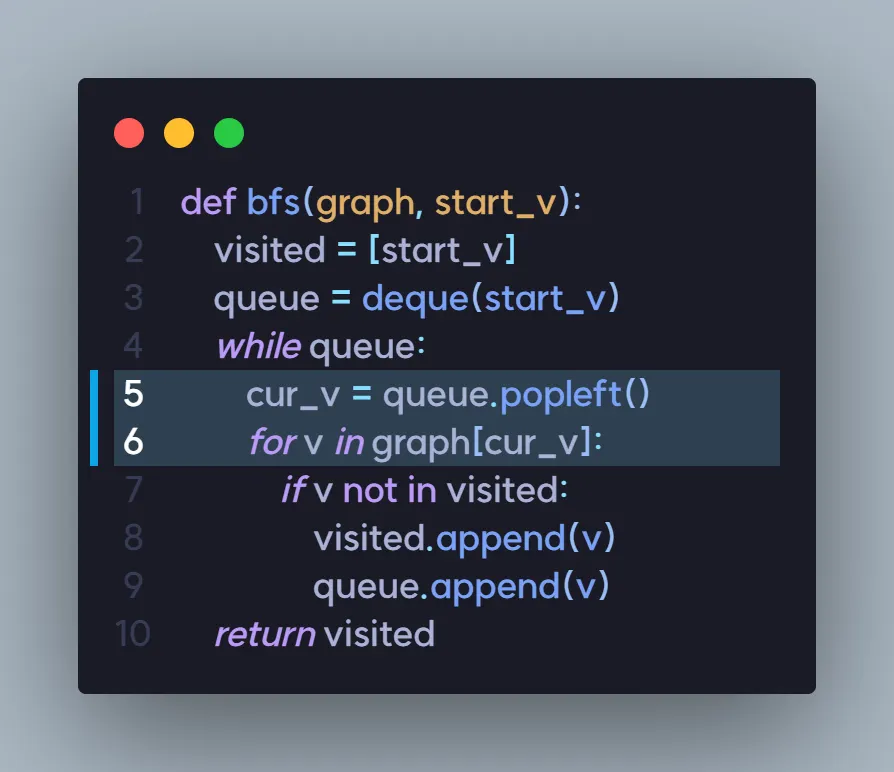
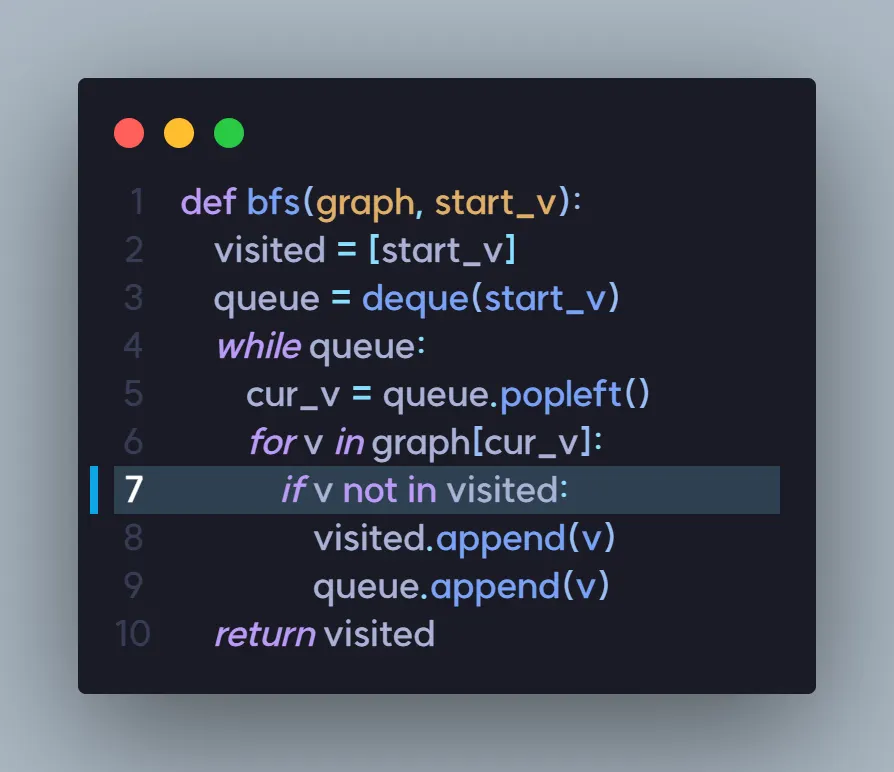
visited | A | B | C | E | |
queue | E |
queue에서 C가 popleft된 후, graph["C"] 즉, ["B", "D"]에 대해 반복문을 돌려 줘야합니다.
B는 visited에 있으므로 넘어 가줍니다.
D는 visited에 없으므로, queue와 visited에 추가해 줍니다.
visited | A | B | C | E | D |
queue | E | D |
queue가 비어있지 않으므로, while 반복문을 돌아야 합니다.
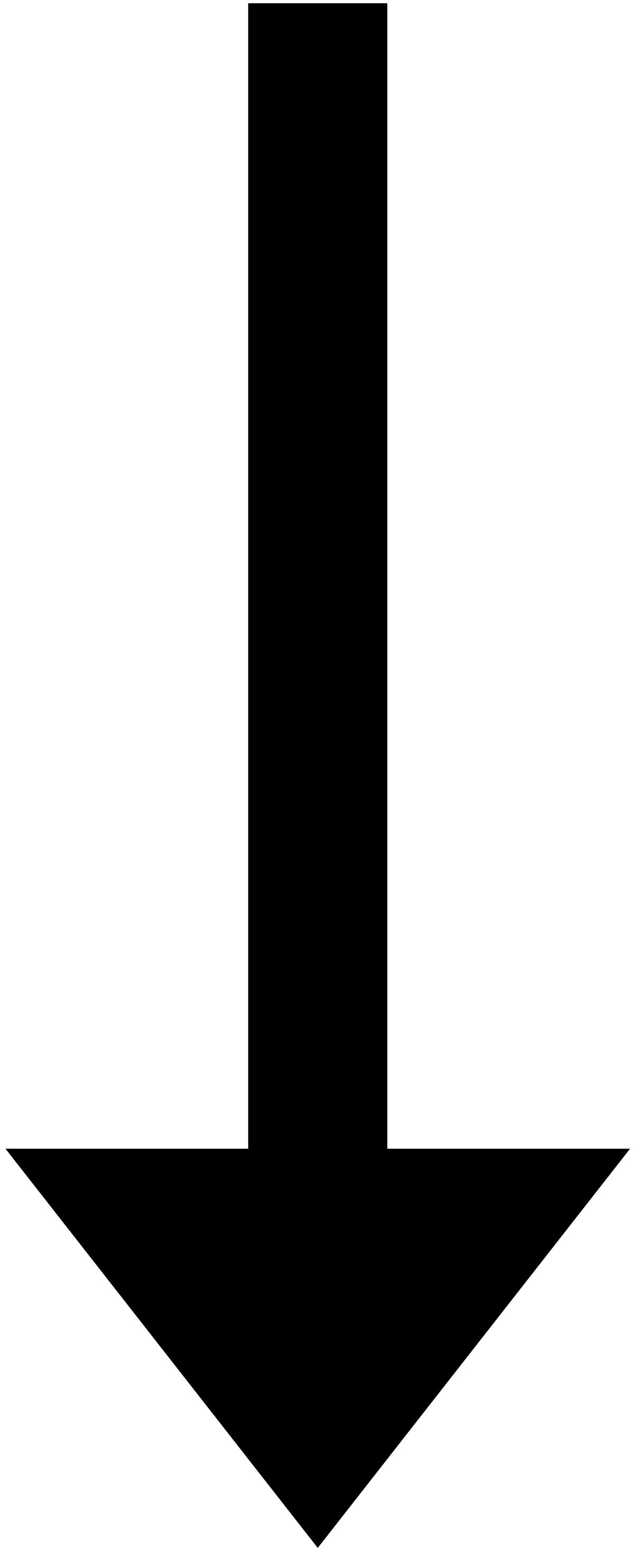
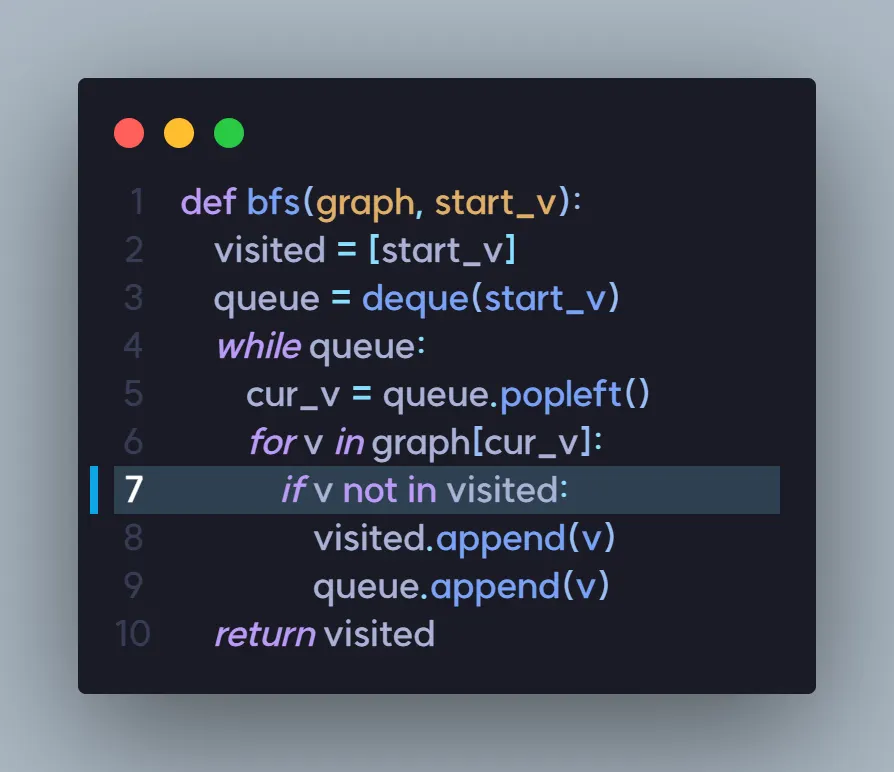
visited | A | B | C | E | D |
queue | D |
queue에서 E가 popleft된 후, graph["E"] 즉, ["B", "D", "F"]에 대해 반복문을 돌려 줘야합니다.
B와 D는 visited에 있으므로 넘어 가줍니다.
F는 visited에 없으므로, queue와 visited에 추가해 줍니다.
visited | A | B | C | E | D | F |
queue | D | F |
queue가 비어있지 않으므로, while 반복문을 돌아야 합니다.
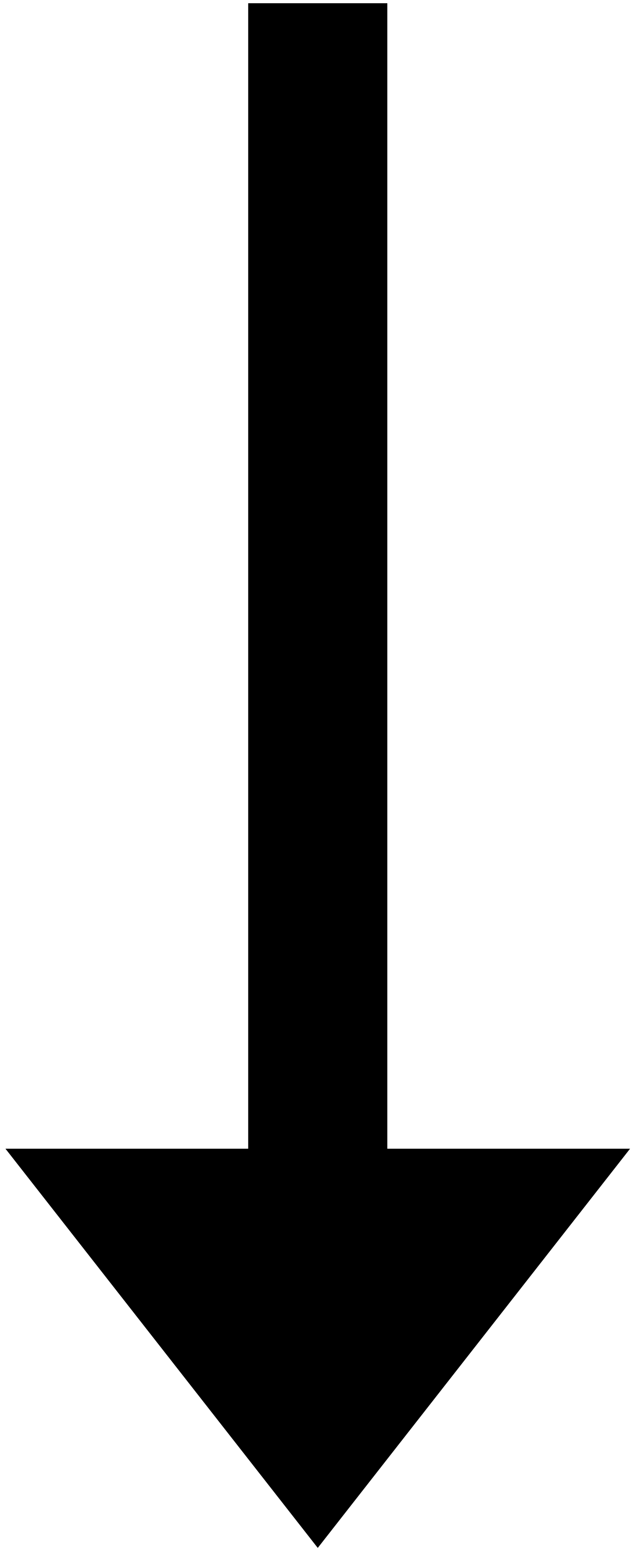

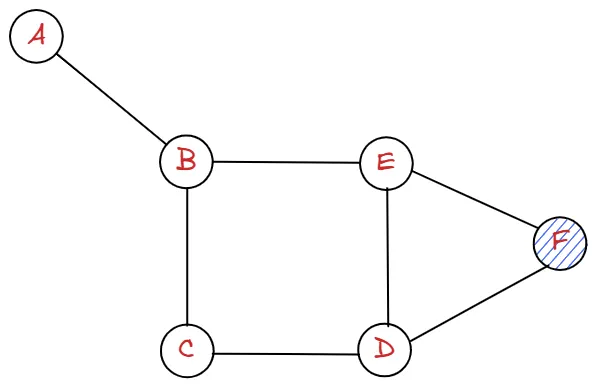
visited | A | B | C | E | D | F |
queue | F |
queue에서 D가 popleft된 후, graph["D"] 즉, ["C", "E", "F"]에 대해 반복문을 돌려 줘야합니다.
C, E, F 모두 visted에 있으므로 넘어가줍니다.
visited | A | B | C | E | D | F |
queue | F |
queue가 비어있지 않으므로, while 반복문을 돌아야 합니다.

visited | A | B | C | E | D | F |
queue |
queue에서 F가 popleft된 후, graph["F"] 즉, ["D", "E"]에 대해 반복문을 돌려 줘야합니다.
D와 E 모두 visted에 있으므로 넘어가 줍니다.
visited | A | B | C | E | D | F |
queue |
queue가 비어있으므로, 반복문을 빠져 나옵니다.
visited가 BFS의 결과로서 트리 순회를 완료하였습니다.
BFS의 코드 구현과 작동 원리에 대해서 알아 보았습니다. tree의 level order traversal과 상당히 비슷함으로, 이 부분을 잘 공부하였다면 큰 어려움 없이 따라 오셨을 겁니다.
BFS 코드는 아주 기본적인 템플릿 코드로서, 머리 속에서 바로바로 구현이 될 수 있어야 합니다!
Depth First Search
DFS는 출발점에 시작해서, 막다른 지점에 도착할 때까지 깊게 이동합니다. 만약 가다가 막히면 다시 그 전 노드로 돌아가고, 또 길이 있으면 깊게 이동하는 식의 과정을 통해 그래프를 순회할 수 있습니다.
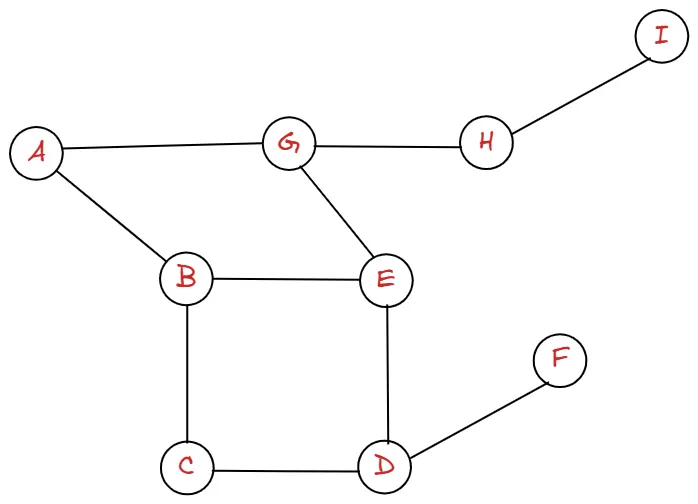
예를 들어 다음과 같은 그래프가 있다고 할 때 A부터 순회를 해보도록 해봅시다. 여러분들도 한 번 해보세요!
답은 !!?
왜 그런 지 한 번 봐 볼까요?
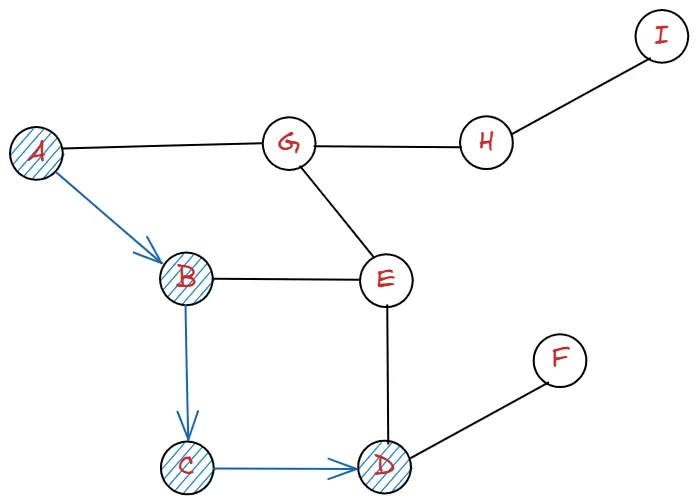
우선 깊게 깊게 파고 들어 D까지 이동합니다. 그 이후로 알파벳 순서를 기준으로 E를 먼저 가도록 합시다.

I까지 간 후 이제 막혀 버렸습니다. 이제 왔던 길을 되찾는 과정을 거칩니다.
H, G, E, D 의 순으로 올라갑니다.
그 후 아직 탐색하지 않는 F를 방문해줍니다.
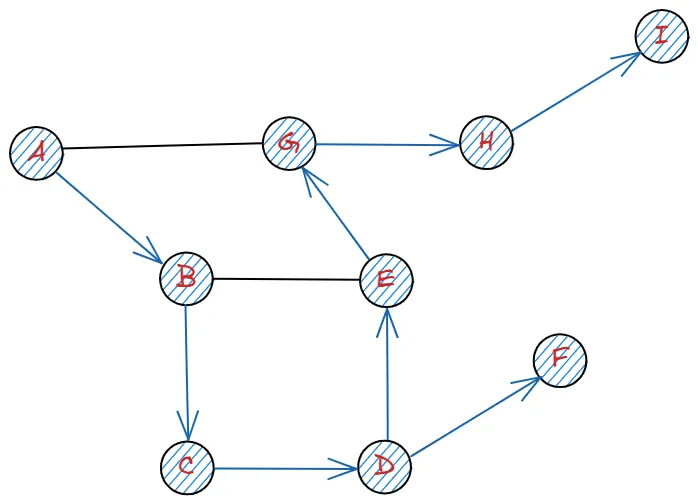
F 이후 마찬가지로 갈 길이 없습니다.
왔던 길인 D, C, B, A 순으로 올라감으로써, 탐색을 마무리 합니다.
이제 탐색 방법을 알았으니, DFS 구현을 알아볼 차례입니다. DFS는 스택과 재귀로 구현할 수 있습니다. 저희는 구현이 쉬운 재귀로 구현 한 방법을 알아보겠습니다.
visited = []
def dfs(cur_v):
visited.append(cur_v)
for v in graph[cur_v]:
if v not in visited:
dfs(v)
Python
복사
tree의 preorder, inorder, postorder의 순회 방식과 매우 유사합니다.
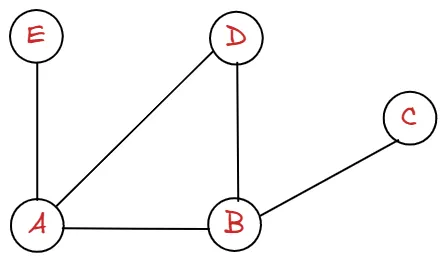
다음과 같은 그래프를 A를 시작점으로 하여, DFS 순회의 내부 구현을 보여드리겠습니다. 재귀와 반복문이 중첩되어 조금 어렵지만, 잘 따라와 주세요!

graph = {
"A": ["B", "D", "E"],
"B": ["A", "C", "D"],
"C": ["B"],
"D": ["A", "B"],
"E": ["A"]
}
Python
복사
현재 위치 | |||||
visited | |||||
누가 call 했지 | |||||
call | |||||
return 여부 | |||||
graph[cur_v] | |||||
graph 0번째 | |||||
graph 1번째 | |||||
graph 2번째 |
다음과 같이 기본 세팅을 하였습니다. 각 항목에 대한 간단한 설명을 하도록 하겠습니다.
•
현재 위치: 지금 내가 무슨 함수를 실행하고 있는 지에 대한 위치를 알려줍니다.
•
visited: 방문한 노드를 적습니다.
•
누가 call 했지: 재귀 특성 상, 함수 안에서 자기 자신을 호출합니다. 자신을 호출한 함수를 적어주며, 함수가 종료되면, 자신을 호출한 함수로 돌아갑니다.
•
call: 새로운 함수가 실행되면, 그 함수를 적어줍니다.
•
return 여부: 함수가 종료되었는지, 아닌지 알려 줍니다.
•
graph[cur_v]: 현재 정점(cur_v)를 기준으로 연결 관계를 보여줍니다.
•
graph 0번째: 현재 정점과 연결된 정점 중 0번째 정점입니다.
•
graph 1번째: 현재 정점과 연결된 정점 중 1번째 정점입니다.
•
graph 2번째: 현재 정점과 연결된 정점 중 2번째 정점입니다.
graph 0,1,2번째 와 관련하여, 아직 차례가 오지 않은 정점에는 를, 종료될 반복문의 정점에는 를 표시 하겠습니다.
를, 종료될 반복문의 정점에는 를 표시 하겠습니다.
graph = {
"A": ["B", "D", "E"],
"B": ["A", "C", "D"],
"C": ["B"],
"D": ["A", "B"],
"E": ["A"]
}
Python
복사
시작점이 A 임으로 dfs(A)를 call 해줍니다. 그 후 visited에 A를 추가해 줍니다. graph['A']
즉, ['B', 'D', 'E']에 대해서 반복문을 돌려 주어야 합니다.
현재 위치 | | ||||
call | dfs(A) | ||||
visited | A | ||||
return 여부 | | ||||
graph[cur_v] | graph[’A’] | ||||
0번째 | B | ||||
1번째 | D | ||||
2번째 | E |

graph['A']의 0번째 원소인, B가 visited에 없으므로 dfs(B)를 call 해줍니다.
이 함수만 완료 되면 B에 관한 반복문이 끝나므로, 로 업데이트 해주겠습니다
로 업데이트 해주겠습니다이제 현재 함수 위치는 dfs(B)입니다.
그 후 visited에 B를 추가해줍니다.
현재 위치 | | ||||
call | dfs(A) | dfs(B) | |||
누가 call 했지 | dfs(A) | ||||
visited | A | B | |||
return 여부 | | | |||
graph[cur_v] | graph['A'] | ||||
0번째 | B | A | |||
1번째 | D | C | |||
2번째 | E | D |

graph['B']즉, ['A', 'C', 'D']에 대해서 반복문을 돌려 주어야 합니다.
0번째 원소인, A가 visited에 있으므로 A에 관한 반복문은 끝났습니다. 로 업데이트 해주겠습니다.
로 업데이트 해주겠습니다.1번째 원소인, C가 visited에 없으므로 dfs(C)를 call 해줍니다. 이 함수만 완료 되면 C에 관한 반복문이 끝나므로, 로 업데이트 해주겠습니다.
로 업데이트 해주겠습니다.이제 현재 함수 위치는 dfs(C)입니다.
그 후 visited에 C를 추가해줍니다.
현재 위치 | | ||||
call | dfs(A) | dfs(B) | dfs(C) | ||
누가 call 했지 | dfs(A) | dfs(B) | |||
visited | A | B | C | ||
return 여부 | | | | ||
graph[cur_v] | graph['A'] | graph['B'] | graph['C'] | ||
0번째 | B | A | B | ||
1번째 | D | C | |||
2번째 | E | D |

graph['C']즉, ['B']에 대해서 반복문을 돌려 주어야 합니다.
0번째 원소인, B가 visited에 있으므로 A에 관한 반복문은 끝났습니다. 로 업데이트 해주겠습니다.
로 업데이트 해주겠습니다.dfs(C)의 반복문 자체가 끝나, dfs(C)는 종료되었습니다.
아직 완료되지 않는 dfs(B)로 돌아갑니다.(누가 call 했지)
현재 위치 | | ||||
call | dfs(A) | dfs(B) | dfs(C) | ||
누가 call 했지 | dfs(A) | dfs(B) | |||
visited | A | B | C | ||
return 여부 | | | | ||
graph[cur_v] | graph['A'] | graph['B'] | graph['C'] | ||
0번째 | B | A | B | ||
1번째 | D | C | |||
2번째 | E | D |

현재 위치는 dfs(B) 입니다.
graph['B']의 2번째 원소인, D가 visited에 없으므로 dfs(D)를 call 해줍니다. 이 함수만 완료 되면 D에 관한 반복문이 끝나므로, 로 업데이트 해주겠습니다.
로 업데이트 해주겠습니다.이제 현재 함수 위치는 dfs(D)입니다.
그 후 visited에 D를 추가해줍니다.
현재 위치 | | ||||
call | dfs(A) | dfs(B) | dfs(C) | dfs(D) | |
누가 call 했지 | dfs(A) | dfs(B) | dfs(B) | ||
visited | A | B | C | D | |
return 여부 | | | | | |
graph[cur_v] | graph['A'] | graph['B'] | graph['C'] | graph['D'] | |
0번째 | B | A | B | A | |
1번째 | D | C | B | ||
2번째 | E | D |

graph['D']즉, ['A', 'B']에 대해서 반복문을 돌려 주어야 합니다.
0번째 원소인, A가 visited에 있으므로 A에 관한 반복문은 끝났습니다. 로 업데이트 해주겠습니다.
로 업데이트 해주겠습니다.1번째 원소인, B가 visited에 있으므로 B에 관한 반복문은 끝났습니다. 로 업데이트 해주겠습니다.
로 업데이트 해주겠습니다.dfs(D)의 반복문 자체가 끝나, dfs(D)는 종료되었습니다.
아직 완료되지 않는 dfs(B)로 돌아갑니다.(누가 call 했지)
현재 위치 | | ||||
call | dfs(A) | dfs(B) | dfs(C) | dfs(D) | |
누가 call 했지 | dfs(A) | dfs(B) | dfs(B) | ||
visited | A | B | C | D | |
return 여부 | | | | | |
graph[cur_v] | graph['A'] | graph['B'] | graph['C'] | graph['D'] | |
0번째 | B | A | B | A | |
1번째 | D | C | B | ||
2번째 | E | D |
현재 위치는 dfs(B)입니다. 그런데 dfs(B)의 반복문이 다 완료되어 있네요?? dfs(B) 역시 종료되었습니다. 아직 완료 되지 않는 dfs(A)로 돌아갑니다.(누가 call 했지)
현재 위치 | | ||||
call | dfs(A) | dfs(B) | dfs(C) | dfs(D) | |
누가 call 했지 | dfs(A) | dfs(B) | dfs(B) | ||
visited | A | B | C | D | |
return 여부 | | | | | |
graph[cur_v] | graph['A'] | graph['B'] | graph['C'] | graph['D'] | |
0번째 | B | A | B | A | |
1번째 | D | C | B | ||
2번째 | E | D |

graph['A']의 1번째 원소인, D가 visited에 있으므로 D에 관한 반복문은 끝났습니다. 로 업데이트 해주겠습니다.
로 업데이트 해주겠습니다.graph['A']의 2번째 원소인, E가 visited에 없으므로 dfs(E)를 call 해줍니다. 이 함수만 완료 되면 E에 관한 반복문이 끝나므로, 로 업데이트 해주겠습니다.
로 업데이트 해주겠습니다.이제 현재 함수 위치는 dfs(E)입니다.
그 후 visited에 E를 추가해줍니다.
현재 위치 | | ||||
call | dfs(A) | dfs(B) | dfs(C) | dfs(D) | dfs(E) |
누가 call 했지 | dfs(A) | dfs(B) | dfs(B) | dfs(A) | |
visited | A | B | C | D | E |
return 여부 | | | | | |
graph[cur_v] | graph['A'] | graph['B'] | graph['C'] | graph['D'] | graph['E'] |
0번째 | B | A | B | A | A |
1번째 | D | C | B | ||
2번째 | E | D |

0번째 원소인, A가 visited에 있으므로 A에 관한 반복문은 끝났습니다. 로 업데이트 해주겠습니다.
로 업데이트 해주겠습니다.dfs(E)의 반복문 자체가 끝나 dfs(E)는 종료 되었습니다.
아직 종료되지 않는 dfs(A)로 돌아갑니다.(누가 call 했지)
현재 위치 | | ||||
call | dfs(A) | dfs(B) | dfs(C) | dfs(D) | dfs(E) |
누가 call 했지 | dfs(A) | dfs(B) | dfs(B) | dfs(A) | |
visited | A | B | C | D | E |
return 여부 | | | | | |
graph[cur_v] | graph['A'] | graph['B'] | graph['C'] | graph['D'] | graph['E'] |
0번째 | B | A | B | A | A |
1번째 | D | C | B | ||
2번째 | E | D |
현재 위치는 dfs(A)입니다. 그런데 dfs(A)의 반복문이 다 완료되어 있네요?? dfs(A) 역시 종료 됩니다. 이제 모든 함수가 종료 되었습니다!!
현재 위치 | | ||||
call | dfs(A) | dfs(B) | dfs(C) | dfs(D) | dfs(E) |
visited | A | B | C | D | E |
return 여부 | | | | | |
graph[cur_v] | graph['A'] | graph['B'] | graph['C'] | graph['D'] | graph['E'] |
0번째 | B | A | B | A | A |
1번째 | D | C | B | ||
2번째 | E | D |
이런 식으로 DFS의 순회 과정을 알아 보았습니다. 재귀에 익숙하지 않으면 이해하기 힘든 과정 일 수 있습니다. 하지만 코드 작성 자체는 어렵지 않으므로, 위의 과정을 반복하여, 최종적으로 머리 속에서 그려지는 것이 익숙해지면 좋을 것 같습니다.
BFS와 DFS 시간 복잡도
각각의 순회는 모든 정점들을 탐색해야 하고 그러기 위해서는 정점에 연결된 edge들을 모두 확인해봐야 합니다. 따라서 BFS와 DFS 시간 복잡도는 입니다.
Copyright. 노씨데브. All rights reserved. 무단 공유 및 배포를 금합니다.